It allows a collection of machines to work as a coherent group that can survive the failures of some of its members.
It means not only a group of machines reach a final decision for a request, but also the state machine is replicated across these machines, so that some failures do not affect the functioning. Raft is a consensus algorithm seeking to be correct, implementable, and understandable.
The thesis is very well written. It is much more comprehensive compared to the NSDI paper. Implementing Raft based on the thesis shouldn’t be too difficult (of course, also not trivial). The author also built a website putting all kinds of helping things there. I read the paper and decide to take some notes here.
There are two key parts sitting in the core of the algorithm:
Leader election
The election is triggered by a timeout. If a server failed to detect heartbeats from the current leader, it start a new term of election. During the term, it broadcast requests to collect votes from other servers. If equal or more than majority of servers reply with a vote, the server becomes the leader of this term. The “term” here is a monotonically increasing logic time. From the perspective of a server receiving the vote request, it decides whether to give the vote based on a few considerations. First of all, if the sender even falls behind the receiver in terms of log index, the receiver should not vote for it. Also, if the receiver can still hear the heartbeats from current leader, it should not vote too. In this case, the requester might be a disruptive server. In other cases, the receiver should vote for the sender.
Log replication
Once a server becomes the leader, it’s mission is simply replicate it’s log to every other follower. The replication means make the log of a follower exactly the same as the leader. For each pair of leader and follower, the leader first identify the highest index where they reach an agreement. Starting from there, the leader overwrite its log to the follower. The leader handles all requests from clients. Once it receives a new request, it first put the request into its own log. Then, it replicate the request to all followers. If equal or more than majority followers (including the leader itself) answer the replication request with success, the leader apply the request into its state machine (this is called commit). The leader put the new log index into its heartbeats, so followers know if the request has been committed, after which each follower commit the request too.
More formal introduction of the core Raft could be found in Fig. 3.1 in the thesis paper. There are also a few extensions to make the algorithm practical to be used in production systems, such as the group management. I also found Fig. 10.1 a very good reference of architecture.
There are quite a lot of implementations of Raft, which could be found here. I also find a project named Copycat, with code here and document here. Copycat is a full featured implementation of Raft in java. Building your own application based on Copycat shouldn’t be too difficult. They provide an example of implementing a KV store based on Copycat in their source code here, which is used as the “Get Started“ tutorial. Another very important reason, why I think Copycat a good reference, is that it emphases the abstraction of state machine, client, server, and operations. Therefore, going through it’s document enhanced my understanding of Raft.
If you don’t want to build your own Raft, may be Copycat is worthwhile a try, though I haven’t any real experience beyond a toy project.
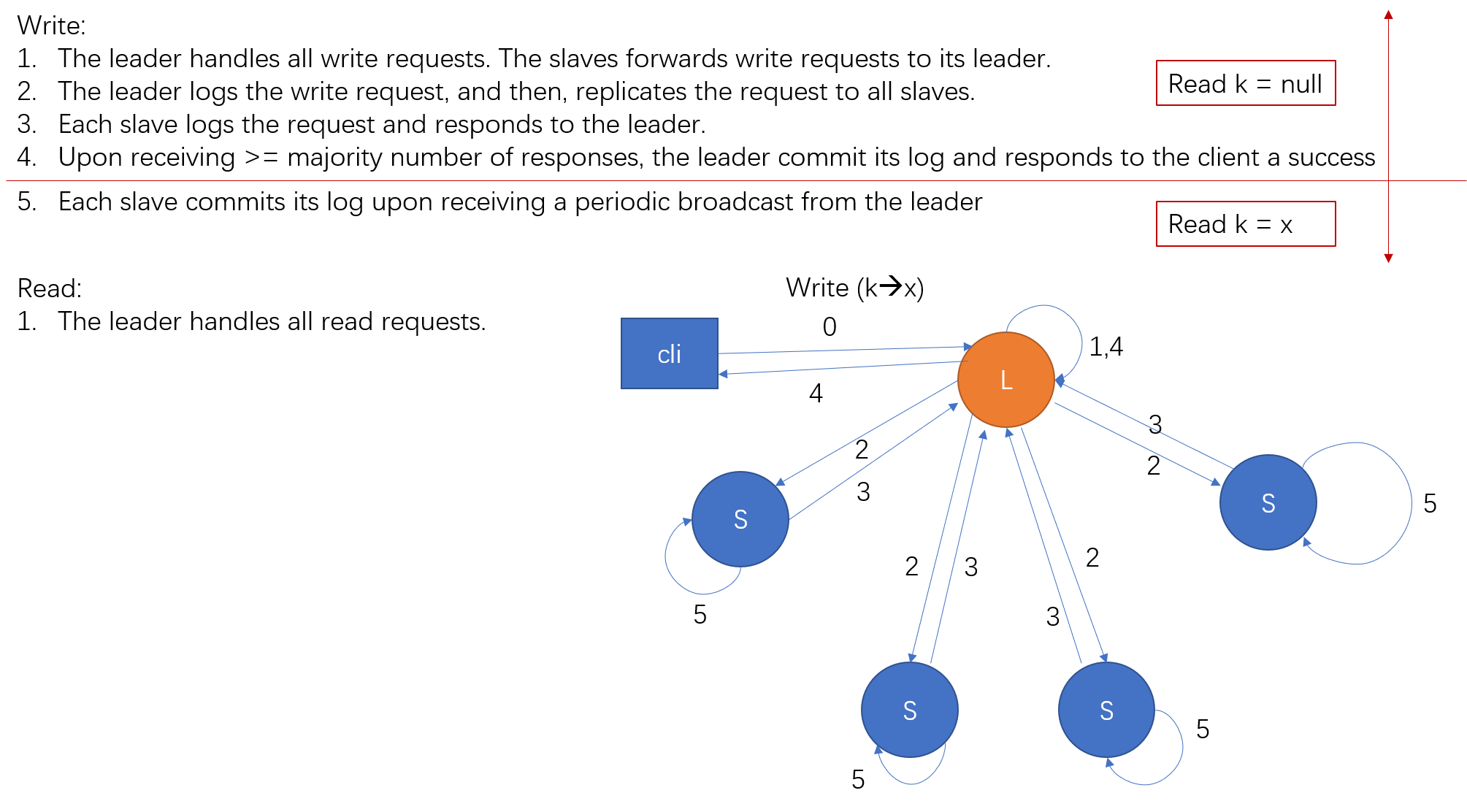
The leader handles the request by putting it to a WAL;
The leader sends the request to all followers;
Each follower puts the received request to its WAL, and responds to the leader;
Once the leader has heard a majority number of responses from its followers, the leader commit the request by applying the WAL to its state machine;
The leader inform the client that the request has been handled properly, and then, put the index of the request into its heartbeat to let all followers know the status of each request;
Once the follower knows that the request has been committed by the leader, the follower commit the request too by applying it to its own state machine.
There are a few key points to understand in the process above:
1.Does the client always know if its request has been handled properly?
No. If the leader commits the request and then crashes, the client will not know if the request has been actually successfully handled. In some cases, the client will resend the request which may lead to duplicated data. It leaves for the client to avoid such kind of duplication.
2.How about the leader crashes before inform its followers that the request has been committed?
If the leader crashes, a follower will be elected to be the next leader. The follower must have the latest state according to the mechanism of Raft. Therefore, the next leader definitely has the WAL for the request, and the request has definitely been replicated across a majority number of hosts. Therefore, it is safe to replicate its state to all followers.
3.Key feature of a consensus algorithm (or strong consistency)?
Under normal situations, if there’s a state change, the key step changing the state should be always handled by a certain node. The state changing should be replicated to a majority number of followers before informing the requester a success. Each read request goes to that certain node as well. Once there’s node failures or networking partitions, the service stop working until returning to the normal situation again.
In one of my recent project, I need to implement a lock service for files. It is quite similar to the lock service of existing file systems. I need to support two modes: write (exclusive) and read (shard). For instance, “R/a/b/c” means a read lock for the file with path “/a/b/c”. Likewise, “W/a/b/c” stands for a write lock.
The interface is pretty straightforward. The user provide a set of locks, e.g., {R/a/b/c, R/a/b/d}, to be locked by our service. One challenge we face is to deduplicate the locks given by the user. For instance, the user may provide a set of locks {R/a/b/c, W/a/b/c}. In this example, we know the write lock is stronger than the read lock, and therefore, the set is equivalent to {W/a/b/c}. We tend to reduce the number of locks, since it is beneficial for checking less conflicts in the steps afterwards.
So far, the deduplication problem sounds quite simple, since we only need to consider locks with exactly the same path. However, we also need to support a wildcard notation, because we have a large number of files under one directory. If we want to lock all files in this directory, we need to generate a huge list of locks, each for a file. With a wildcard, we lock all files under “/a/b/“ with “R/a/b/*”. The wildcard makes the deduplication problem much more complicated.
We first clarify the coverage of locks by a concrete example:
1
W/a/b/* > W/a/b/c > R/a/b/c
Given a large set of locks, a very simple algorithm is that we compare each pair of locks. If one is stronger than the other, the weaker one is throw away. The result set contains only locks where no one is stronger than other locks. This algorithm’s complexity is O(n*n) which is slow if the given set is large. So, I try to find a faster algorithm.
After some thoughts, I developed an algorithm with complexity O(n), which constructs a tree on the set of locks. Each tree node has the following attributes:
1 2 3 4 5 6 7 8
class Node { String name; //the name of the node String mode; //"W" or "R" Node parent; //the parent of the node boolean mark = false; //mark=true if there's at least one W node in its subtree Map<String, Node> children = new HashMap<>(); //the children of this node ... }
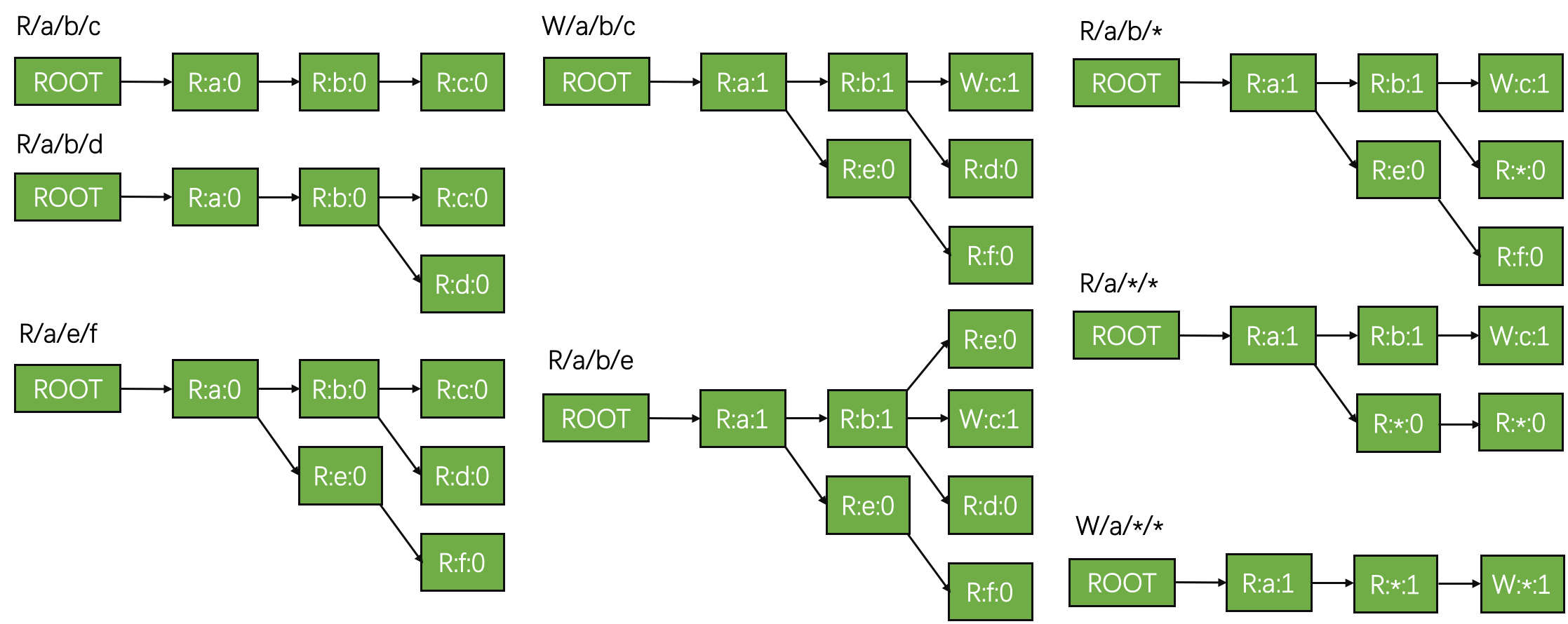
We now explain how to construct a lock tree with a concrete example.
In the figure above, we show inserting a set of locks into an empty lock tree. Each node is represented with a string “mode:name:mark”.
Step 1~3: Inserting the first three locks {R/a/b/c, R/a/b/d, R/a/e/f} is straightforward. Step 4: Then, inserting the 4th lock, i.e., “W/a/b/c”, has two effects: (1) upgrade the original “R” lock of /a/b/c to “W” mode; (2) mark the path of “/a/b/c” from 0 to 1. Step 5: The 5th lock “R/a/b/e” is the same with the first three. Step 6~7: Then, the 6th lock “R/a/b/*“ contains a wildcard. Having a “R” wildcard means replacing all unmarked nodes (“R:e:0” and “R:d:0”) with a “R:*:0” node, in its parent’s subtree (the parent is “R:b:1” in this case). Similarly, inserting “R/a/*/*“ first removes all unmarked nodes in “R:a:1”‘s subtree, i.e., “R:e:0”, “R:*:0”, and “R:f:0”, and then insert new nodes with wildcard. Step 8: Finally, inserting a “W” mode lock with wildcard means deleting all nodes in the subtree of “R:a:1” (the wildcard node’s parent) and then insert the new nodes.
After constructing the lock tree, each path from root to leaf is a lock in our deduplicated result set. In practice, a hashmap may already solve most duplicated cases. We rarely encounter extreme cases as shown in the example above. The algorithm briefly described above is only for fun :). I didn’t mention paths with different lengths since they could be put into different trees, which is therefore not a real problem.
I didn’t elaborate all cases in the example above, which is more complicated. A sample implementation of the algorithm could be find here. The output is as follows:
An admission control system takes care of two parts: action and resource. As a concrete example, let’s assume you are a sales manager. A typical business is viewing the orders made by all sales man in your group. Here, viewing the orders is the “action” part, while the orders made by your group is the “resource” part.
Given a user account, an admission control system tells which actions the user could take on which resources. For a website, the action is usually represented with a URI. For instance,
1 2 3
"/orders/view" -> view the orders "/user/delete" -> delete a user "/user/update" -> update a user's profile
A typical way of managing the actions is through a layered representation of users, roles, and permissions. A user belongs to a role, and a role is composed of a set of permissions. Each permission is linked to a URI for instance. For convenience reasons, people usually add additional layers to the three-layer structure. For example, a “permission group” layer makes it easier for the manager to assign permissions when the number of permissions is too large.
1
user -> role -> permission
Representing the resource is nontrivial. Before that, you need domain knowledge to understand the structure of the resource. In our example of sales manager, the resource are orders which could be managed in a tree. The manager can see all orders within her subtree, while a sales man cannot see orders from her siblings. In this case, the resource is put into a tree as follows.
1 2 3 4 5 6 7
manager -- sales man 1 | -- sales man 2 | -- sales man 3 -- agent 1 | -- agent 2
You may maintain multiple trees, each for a logic organization. For instance, one tree for sales and another for operators. Each order is linked to a node on the tree. When a action arrives, e.g., “/orders/view/1” where “1” is the order id, we check if the linked node of this order entry in DB. If the node is within the user’s subtree, the admission is granted, otherwise denied.
Last but not least, be sure to use a white list for the super user. In other words, the super user should not go through the admission control system. Otherwise, when the admission control system is down, you can do nothing at all without permission.
准确的说《乌合之众》是指“The Crowd——A Study of the Popular Mind”,作者是Gustave Le Bon,一位1931年离世的法国作家。我所读的版本是由广西师范大学出版社出版的,由冯克利翻译的版本。有意思的是这本书正文只有32开的183页,而其中1-29页是Robert K. Merton撰写的读后感,所以在阅读正文之前已经有非常详尽的对于书的评论了。
I recently got a chance of experimenting mapreduce over several opensource object storages. Openstack swift is definitely one well known object storage service. However, I found it non-trivial to set it up for evaluation. Therefore, I put some notes below.
This article is only for os=Ubuntu 14.04 and swift=liberty. I noticed that the newer versions of swift is with much better documentation, which is much easier to follow. The appendix contains my early trials of installing swift from source.
Part 1. Fundamentals and Architecture in “Openstack Swift - Using, Administering, and Developing for Swift Object Storage”
Make sure you have some sense for concepts including user, role, tenant, project, endpoint, proxy server, account server, object server, rings, and etc.
To my understanding, they are:
user: a real user, or a service
role: role of users, corresponding to a set of permissions
tenant = project: a set of users
endpoint: the entry point urls of openstack services
proxy server: handling user requests in swift
account server: handling user account in swift, also used as domain or primary namespace
object server: handling object storage in swift
rings: the consistent hashing algorithm used by swift
keystone: the authentication service in openstack. Key concepts on keystone can be found here
Setup keynote and swift
Install dependencies
Install MariaDB (or MySQL) and memcache following page
Install keystone following page1 and page2. Note that if you want to run mapreduce over swift, you can not use the TempAuth approach. Read this page for more details.
Install swift following page1, page2, and page3. You can start the swift service with
1
swift-init all start
Setup Hadoop
Setup Hadoop with version >= 2.3 and configure it following page1 and page2.
Make sure SwiftNativeFileSystem is in the classpath, read this page for any problem you find.
Configure etc/hadoop/core-site.xml,add following contents:
<configuration> <property> <name>fs.swift.impl</name> <value>org.apache.hadoop.fs.swift.snative.SwiftNativeFileSystem</value> </property> <property> <name>fs.swift.service.SwiftTest.auth.url</name> <---SwiftTest is the name of the service <value>http://127.0.0.1:5000/v2.0/tokens</value> <---the ip:port should point to keystone. Make sure having "/tokens" there. </property> <property> <name>fs.swift.service.SwiftTest.auth.endpoint.prefix</name> <value>/AUTH_</value> </property> <property> <name>fs.swift.service.SwiftTest.http.port</name> <value>8080</value> <--- the same with that in proxy-server.conf </property> <property> <name>fs.swift.service.SwiftTest.region</name> <value>RegionOne</value> </property> <property> <name>fs.swift.service.SwiftTest.public</name> <value>true</value> </property> <property> <name>fs.swift.service.SwiftTest.tenant</name> <value>admin</value> <--- name of the project, not the role! </property> <property> <name>fs.swift.service.SwiftTest.username</name> <value>admin</value> <--- user name </property> <property> <name>fs.swift.service.SwiftTest.password</name> <value>adminpassword</value> <--- password </property> </configuration>
Verify all setup
create a container (swift post nameofcontainer). Important! the name should be only consist of letters. No ‘_’ is allowed.
upload a file (swift upload nameofcontainer nameoffile).
hdfs dfs -ls swift://nameofcontainer.SwiftTest/. This should show you files you uploaded previously.
Install the latest liberasurecode (as per some post, may not be necessary)
1 2 3 4 5 6 7 8 9
sudo apt-get install build-essential autoconf automake libtool cd /opt/ git clone https://github.com/openstack/liberasurecode.git cd liberasurecode ./autogen.sh ./configure make make test sudo make install
Install the Swift CLI
1 2 3 4
cd /opt git clone https://github.com/openstack/python-swiftclient.git cd /opt/python-swiftclient; sudo pip install -r requirements.txt; python setup.py install; cd ..
I run into a problem of invalid format of the requirement.txt. You may need to do some editing in that case.
Install the Swift
1 2 3
cd /opt git clone https://github.com/openstack/swift.git cd /opt/swift ; sudo python setup.py install; cd ..
The above is from the swift book. But I realized I still need to run “sudo pip install -r requirements.txt” before the setup*
Another issue I found is that it takes forever to pip install cryptography in the requirements.txt. I searched in Google where some guy said it took 20 min for building. For me, after 20 min, it still hanged there.
I tried to install all dependencies manually, as follows without the cryptography. After that, it was installed successfully:
1 2 3 4 5 6 7 8 9
Requirement already satisfied (use --upgrade to upgrade): cryptography in /usr/local/lib/python2.7/dist-packages Requirement already satisfied (use --upgrade to upgrade): idna>=2.0 in /usr/local/lib/python2.7/dist-packages (from cryptography) Requirement already satisfied (use --upgrade to upgrade): pyasn1>=0.1.8 in /usr/local/lib/python2.7/dist-packages (from cryptography) Requirement already satisfied (use --upgrade to upgrade): six>=1.4.1 in /usr/local/lib/python2.7/dist-packages (from cryptography) Requirement already satisfied (use --upgrade to upgrade): setuptools>=11.3 in /usr/local/lib/python2.7/dist-packages (from cryptography) Requirement already satisfied (use --upgrade to upgrade): enum34 in /usr/local/lib/python2.7/dist-packages (from cryptography) Requirement already satisfied (use --upgrade to upgrade): ipaddress in /usr/local/lib/python2.7/dist-packages (from cryptography) Requirement already satisfied (use --upgrade to upgrade): cffi>=1.4.1 in /usr/local/lib/python2.7/dist-packages (from cryptography) Requirement already satisfied (use --upgrade to upgrade): pycparser in /usr/local/lib/python2.7/dist-packages (from cffi>=1.4.1->cryptography)
You can custermize the storage policy as per the swift book, but it is optional.
Build the rings
The 3 parameters are part_power, replicas, min_part_hours
part_power: the number of partitions in the storage cluster. The typical setting is log_2 ( 100 maximun number of disks ). For this setup, it is log_2 (100 1) which is close to 7.
replicas: in this setup, there is only one drive. Therefore, only 1 replica is allowed.
min_part_hours: the default is 24 hours. Tune it as per the swift book or the official document.
You can use a disk or chop off disk space from existing disk to provide storage for swift. Follow the step 2 of this article. Copied here:
Attach a disk which would be used for storage or chop off some disk space from the existing disk. Using additional disks: Most likely this is done when there is large amount of data to be stored. XFS is the recommended filesystem and is known to work well with Swift. If the additional disk is attached as /dev/sdb then following will do the trick:
Chopping off disk space from the existing disk: We can chop off disk from existing disks as well. This is usually done for smaller installations or for “proof-of-concept” stage. We can use XFS like before or we can use ext4 as well.
Also, you need to mount automatically after system reboot. So put the mount command line into a script, e.g., /opt/swift/bin/mount_devices. Then add a file start_swift.conf under /etc/init/ with content
1 2 3 4
description "mount swift drives" start on runlevel [234] stop on runlevel [0156] exec /opt/swift/bin/mount_devices
Make sure to make the script runnable
1
chmod +x /opt/swift/bin/mount_devices
Add the drives to the rings
The single parameter 100 is the weight for load balancing. Note that the partition1 in the command is in the path of /srv/node/partition1. If you change the path, you need to change both places. It is not the name of the device in /dev/sda, for example. Make sure about the IPs and the PORTs. They are the address of the processes (account, container, and object). I was blocked by the port for quite a while, simply because the default ports in the conf files are different from the ones used below (not sure why…).
We rely on tempauth for authentication in this setup. If you are using keystone, follow this post or this one.
First, start the memcache:
1
service memcached start
Add your users to proxy-server.conf under the tempauth block.
1 2 3 4 5 6 7 8 9 10
[filter:tempauth] use = egg:swift#tempauth # You can override the default log routing for this filter here: ... # <account> is from the user_<account>_<user> name. # Here are example entries, required for running the tests: user_admin_admin = admin .admin .reseller_admin user_test_tester = testing .admin user_test2_tester2 = testing2 .admin user_test_tester3 = testing3
Start the services after making sure the conf files are right, especially the ip and port. The ip is typically set to 0.0.0.0 and the port should be the same as adding the drives.
* Hostname was NOT found in DNS cache * Trying 127.0.0.1... * Connected to 127.0.0.1 (127.0.0.1) port 8080 (#0) > GET /v1/AUTH_admin HTTP/1.1 > User-Agent: curl/7.35.0 > Host: 127.0.0.1:8080 > Accept: */* > X-Storage-Token: AUTH_tka1a0d192e57746839c1749f238ba5419 > < HTTP/1.1 200 OK < Content-Length: 12 < X-Account-Object-Count: 0 < X-Account-Storage-Policy-Policy-0-Bytes-Used: 0 < X-Account-Storage-Policy-Policy-0-Container-Count: 1 < X-Timestamp: 1484824088.30547 < X-Account-Storage-Policy-Policy-0-Object-Count: 0 < X-Account-Bytes-Used: 0 < X-Account-Container-Count: 1 < Content-Type: text/plain; charset=utf-8 < Accept-Ranges: bytes < X-Trans-Id: txf57c870a9ba146d9947d0-005881a5cd < X-Openstack-Request-Id: txf57c870a9ba146d9947d0-005881a5cd < Date: Fri, 20 Jan 2017 05:53:17 GMT < mycontainer * Connection #0 to host 127.0.0.1 left intact
I was blocked here for quite a while simply because the port in the proxy-server.conf is 6202, not 6002. Be careful!!!
If you get something wrong, go to the log file (at /var/log/swift/all.log) and see the error message there.
You can further verify the setup by creating a container and upload/download a file with
1 2
curl -v -H 'X-Storage-Token: AUTH_tka1a0d192e57746839c1749f238ba5419' -X PUT http://127.0.0.1:8080/v1/AUTH_admin/mycontainer swift -A http://127.0.0.1:8080/auth/v1.0/ -U admin:admin -K admin upload mycontainer some_file
In the last command line, we use swift client instead of curl. There are other subcommand other than upload. There are delete, download, list, post, and stat. To avoid putting the url and user info in every command, one could put the following into .bashrc
One useful way of controlling these processes is by
1
swift-init all start/stop/restart
Setup on multiple nodes
The plan of deployment depends on the hardware. One need to read the part IV of the swift book before that. I found this article very well writen. One can learn the way of deployment for a small cluster.
There are two steps for each input format, namely, getSplit and recordReader. GetSplit transforms the original input data into splits, one split for each mapper. Typically, if a big file is feed into mapreduce, it will be divided into splits of block size (e.g., 64M or 128M). However, if small files are provided, mapreduce will treat each file as a split. RecordReader turn each split into key value pairs, which are used by the mapper later.
In this article, I use several examples to explain how an inputformat be implemented. I’m greatly influenced by a few great references, such as this and this.
The first example is from book “Hadoop: The Definitive Guide”. WholeFileInputFormat treats each individual input file as a value. We do not need to implement our own getSplit function. Once the isSplitable function returns false, no file will be divided. Each file is treated as a split for the mapper.
1 2 3 4 5 6 7 8 9 10 11 12 13
public class WholeFileInputFormat extends FileInputFormat<NullWritable, BytesWritable> { @Override protected boolean isSplitable(JobContext context, Path filename) { return false; }
Since each file is a split, the inputSplit of the record reader is actually a FileSplit. In the example code below, each returned value is the whole content of the file. The key is null in this example, which can also be the name of the file obtained from the fileSplit.
public void close() throws IOException { //do nothing } }
I also think the TeraInputFormat a good example. The key difference from the previous example lies in the input file format of terasort. According to the document, each input element is a 100 byte array, with the first 10 bytes as key and the left 90 bytes as value. This raises a challenge for dividing the input file into splits with exactly multiple of 100 bytes. In the code below, the getSplits simply invokes super.getSplits, ignoring the format issue. Then, in the record reader, the offset is adjusted to the next multiple of 100.
static class TeraRecordReader extends RecordReader<Text, Text> { private FSDataInputStream in; private long offset; private long length; private static final int RECORD_LENGTH = 100; private byte[] buffer = new byte[100]; private Text key; private Text value;
One of the most common reason of customizing your own input format is for combining small files into fewer bigger ones. For this purpose, we still need to disable the split of files. Note that the implemented CombineWholeFileInputFormat extends CombineFileInputFormat which helps to turn the input split into a combine file split (the size of each split could be tuned) which may contains multiple small files. Each individual file could be retrieved with an index as shown in the record reader below.
public class CombineWholeFileRecordReader extends RecordReader<Text, BytesWritable> { private WholeFileRecordReader reader; private String fileName; public CombineWholeFileRecordReader(CombineFileSplit split, TaskAttemptContext context, Integer index) throws IOException, InterruptedException { FileSplit fileSplit = new FileSplit(split.getPath(index), split.getOffset(index), split.getLength(index), split.getLocations());
fileName = fileSplit.getPath().toString();
reader = new WholeFileRecordReader(); reader.initialize(fileSplit, context); }
public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
}
public boolean nextKeyValue() throws IOException, InterruptedException { return reader.nextKeyValue(); }
public Text getCurrentKey() throws IOException, InterruptedException { return new Text(fileName); }
public BytesWritable getCurrentValue() throws IOException, InterruptedException { return reader.getCurrentValue(); }
public float getProgress() throws IOException, InterruptedException { return reader.getProgress(); }
public void close() throws IOException { reader.close(); } }
Summary
This article demonstrated a few sample implementations of input format for a mapreduce job. The basic idea is first divide the whole input data into splits and then read each split with a record reader. Usually, there are already plenty of base input formats that can be leveraged for customizing into more sophisticated ones.
Artificial Intelligence (AI) or Human Intelligence (HI)?
It is not always obvious to determine using AI or HI. If you feel confident to have sufficient data to train sophisticate models, you may prefer using AI. Otherwise, using HI based rules is a more straight way tackling the problems. In practice, a hybrid solution combining both AI and HI is usually a wise choice.
Classification or Regression?
It all depends on the output of the problem. If the outcome is continuous, use regression, otherwise classification. In the digital world, nothing is really continuous. So, if there are too many categories, use regression is a wiser choice.
Do I need preprocessing?
It is rare case that no preprocessing is required. Data usually contains a lot of noise. If the raw data is feed into the learning algorithm, unpredictable outcome may be obtained. Filtering the extraneous data before doing the learning, and most important, also apply the filter before applying the algorithm in your real system. Once you encounter an extraneous event, use HI to determine the output to your end user.
Complex or Less complex?
In the world of learning algorithm, the complexity of the problem is important to choose to apply a “legacy” algorithms like random forest, SVM, or to apply a “cutting-edge” algorithm like CNN. Though DNN beats the smartest people in some areas, it is still quite big for some applications, e.g., activity classification on smartphones. Also, keep in mind that those super powerful algorithms need tons of data as learning input. So, before tasting the cutting-edge techniques, be sure to prepare enough “food” for them.
How to avoid over-fitting?
The cue comes from cross validation. Depending on how much data you have, you make take out 30% data for testing, and the left 70% for training. Or, you may split the whole data set as 10 splits. You take out 1 split for testing and the left 9 splits for training. If you have only few data, use leave one out cross validation.
What’s the cost?
Learning algorithms typically treat all output result neutrally, which however is rare in practice. So, be sure to consider about your cost function, and apply it to the learning algorithm. There are a few ways of applying a cost function given a learning algorithm as a blackbox.
How domain-knowledge comes in?
In general, domain knowledge belongs to HI. Here, I simply want to emphasis that domain knowledge may come in multiple ways. For example, the output of a classification algorithm may be smoothed with a HMM smoother powered by domain knowledge. Also, choosing the features requires deep understanding about the problem to solve. Make a stretch algorithm framework for the problem and then feed more and more domain knowledge in brain to make it better.
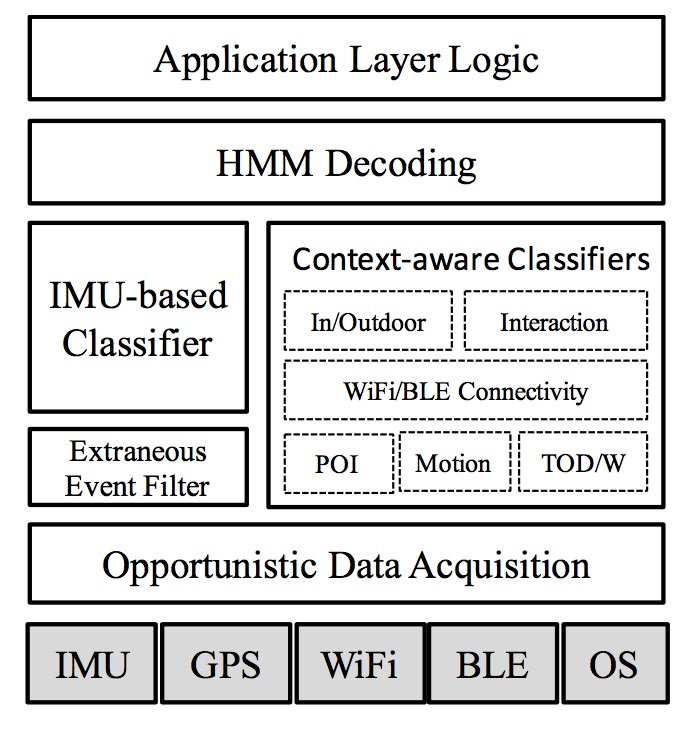
Finally, I want to put a picture of the architecture that I designed for transportation activity detection on smartphones.
Particle filtering is essentially a heuristic continious search process. Each particle represents a probe of the whole search space. Thus, the number of particles represents the size of the search space. There are a few key steps in the search process: initialization, update weight, andd resampling. Each of these steps can be heuristically tuned following the physic world rules. A good example of applying particle filtering can be found in “Robust Indoor Localization on a Commercial Smart-Phone”, CMU TR 2011. In the paper, they adopted Importance Resampling which is a typical approach by selecting these important particles each iteration. Alternatively, another popular approach is to learn the distribution of the particles and re-generate them based on the learnt model. For example, we assume the particles follow a Normal distribution (learnt based on mean and stddev of their positions), and the observation implies another Normal distribution (pre-knowledge), we can then use a joint distribution to generate the new batch of particles. Two must read papers are Magicol and this one.
Forward Error Correction
The purpose of FEC is to ease the correction of error packets in a packet-based network. Though there are various ways to accomplish this goal, a easy-to-follow paper is “Effective erasure codes for reliable computer communication protocols”, Sigcomm Comput. Commun. Rev. 1997. The key idea is to treat N packets as N unknowns, and generate M (M greater than or equal N) un-collinear equations such that any N equations (among M) can derive the original N packets. There is actually no inherent difference between FEC and network coding. The key idea of network coding is to exploit the broadcast nature of wireless communication to save as much bandwidth as possible. Dina Katabi has been working on this back to a few years ago, which could be found here.
Periodicity Detection
There are basically two mechanisms: short-time FFT and auto-correlation. A very easy-to-follow paper “On Periodicity Detection and Structural Periodic Similarity” SDM’05. The key idea of that paper is to fuse them for robustness. The paper is written in an interesting fashion. This paper also gives a high-level description on FFT.
Periodicity detection is actually independent to the sensor. However, with different sensors, the specific approach may vary a little bit. A very good reference using RGB camera sensor is “Real-Time Periodic Motion Detection, Analysis, and Applications” CVPR 2000. The approach in the reference paper is quite intuitive and easy to follow.
Though detecting periodic activities has been well studied, it is still challenging to achieve online counting. A good practice for counting is based on a state machine with two states: (1) periodicity detection: where frequency analysis (FFT) is applied to a sliding window and peak energy ratio to tell if a periodic activity is observed; (2) edge detection: the rising/falling edges are counted. There are a few important thresholds. First, the peak energy ratio which describes how “higher” the energy of the peak should be above the ambient. Second, the threshold used to detemine if there’s a rising/falling edge. These choices require definitely domain knowledge and should use real data to learn them.
Local Regression
Regression is used to predict the output of a system based on existing observations. Local regression is thus used to account for locality which is a common phenomena in many physic world scenarios. Andrew Ng’s CS229 lecture notes is a good tutorial for understanding this concept. One example of applying local regression is in the Modellet paper, as well as in “Refining WI-FI Based Indoor Positioning” ISCAICT, 2010. The key technology for avoiding overfitting is leave-one-out cross-validation (LOOCV). The key idea of cross-validation is to ensure good performance on an independent test set. More details can be found in reference paper.
Modulation
A easy-to-follow guide to modulation could be found in here.
Rolling Shutter
One widely used exposure control is called rolling shutter where each row has a different exposure starting time. Therefore, if the scene is varying frequently, the captured data may vary from row to row. One brief introduction of rolling shutter can be found in “Energy characterization and optimization of image sensing toward continuous mobile vision” Mobisys’13. The exposure time for each row is exactly the exposure time of the camera which depends on the lighting condition. The difference of the starting times between adjacent rows is called row readout time, which depends on the hardware. Then, to analyse a shining light signal in the frequency domain, the sampling interval is deemed to be the readout time, and the sampling duration is the exposure time. A special case is that if the sampling duration is the multiple of the signal period, the signal is undetectable. Note that the exposure time doesn’t affect the highest detectable frequency, however, the longer the sampling duration, the lower the SNR.
Using rolling shutter to detect a shinning LED light source is feasible in theory. However, due to factors like imperfect sensor, exposure time, and background interference, the SNR is typically low. In common office condition, the recommended illumination level is 300 to 500 Lux. Therefore, it is impractical to apply this technique under such conditions.
IMU Sensor Fusion
Modern mobile devices ship with low-cost IMU sensors, i.e., accelerometer, gyroscope, and compass. Ideally, they can be used to track the orientation of the rigid body of the device. However, suffering from the drift issue, the sensor outputs cannot be directly used. A common way of dealing with such problems is fusing the readings from various sensors. This in general belongs to the field of Mechatronics and Robotics, and thus the derivation is quite complicated. Fortunately, we can leverage existing work described in the paper “An efficient orientation filter for inertial and inertial/magnetic sensor arrays” by Sebastian Madgwick in 2010. His code is distributed publicly and used by a lot of open source projects like this and this is a port of the algorithm in C.
Recently, I found this place does a very good job explaining the key points on sensor fusion, and a copy in pdf is here.
Random Sample Consensus
Random Sample Consensus is usually referred to as RANSAC, which is an iterative method to estimate parameters of a model from a set of observations. The key idea is very straightforward. The algorithm starts by randomly selecting a subset of all observations to train the unknown parameters of the model. Then, it tests the remain observations and count how many of them fits the model. If the ratio is higher than a threshold, the model is considered acceptable. Otherwise, the model is rejected. The algorithm goes through a finite number of iterations to find the optimal model with the highest consensus ratio. There are two key parameters, namely thresholds of consensus and acceptable model. In order to get a good estimation, the user should have solid domain knowledge of the distribution of the data and outliers. Examples and implementation in C++ could be found at here and here.
One may wounder why not using all data to train the model. The answer is that, sometimes, it is unnecessary to use all data. One example is when you want to calculate the transform matrix from one point cloud to another.
Diff Algorithm
Diff is an important algorithm in various applications such as finding the difference in two code segments. There are various ways of doing this where a representive one is described in the paper “An O(ND) Difference Algorithm and Its Variations”. One salient point of this paper is the formulation of the problem using Edit Graph. A C# implementation and discussions cound be found here. A nicer description can be found here.
Kernel Density Estimation (KDE)
Kernel density estimation (KDE) is a technique typically used to smooth the discrete density function, or more precisely the histogram, learnt from a finite set of samples. For instance, we observed 10 samples of the RSSI of a Wi-Fi access point, ranging from -40dB to -90dB. Then, we can derive the histogram distributing the samples in to 10dB sized bins. However, due to the limited number of samples, we may result in a coarse-grained shape. KDE is used to deal with such situations. The key idea is to “leak” some probability density into neighboring bins. To achieve this goal, KDE involves a kernel, commonly uniform, triangular, bi-weight, normal, or others, and apply it across the histogram. An intuitive example could be found on the Wikipedia with normal kernel. Thus, to perform KDE, one needs to choose an appropriate kernel, as well as a bandwidth for the kernel. Generally, KDE is an empirical method to make the discrete probability density function more reasonable. However, one definitely need to understand the domain knowledge to ensure that KDE really makes some sense.
Apriori Algorithm
Apriori is a classic algorithm for mining association rules in a large dataset. One famous application of Apriori is to mine common merchandise itemset bought by customers. There are two key metric in Apriori, i.e., support and confidence. Support quantify the number of transactions containing the itemset of interest. For instance, there are a total of 1000 transactions where 100 of them contains both bread and butter, then the support ratio is 100/1000=0.1. Another important metric is the confidence which measures the reasoning confidence. Use the same example. If 200 transactions contains bread and only 100 of them have butter, then the confidence is 100/200. In other words, we have 50% confidence to say that if someone buy break, she will also buy butter. Before mining the dataset, one need to specify these two metrics. Typically, confidence is set to a very high value like 99% to ensure the derived rules are significant and meaningful. The ratio of support depends heavily to the domain knowledge. In the market transaction example, support needs to be high to motivate the rearrange the goods being aware of the cost. However, in some cases, we focus more on the confidence, where the support could be low.
The algorithm works in a bottom up way. Apriori first finds out all one-item sets with support higher than the chosen metric. Then it elaborate all combinations of one-item sets to form two-item sets. The process keeps on until no more higher level set satisfies the support metric. Then, Aporiori applies the confidence metric to filter out invalid itemsets. Apriori is with many implementations which can be found easily.
Installing Octave on the latest OSX can be error prone. One may download the Octave-Forge bundle from sourceforge here which however is large and also a bit out of date.
Alternatively, if you use homebrew to do this, please be ware of a few traps. Here are the steps I adopted to successfully install Octave. If you do not have Xcode or Homebrew installed yet, please refer to Google to get them installed properly.
It may take quite some time to install gcc from source. If you cannot wait, do xcode-select –install before install gcc. This will have mac install a pre-compiled version which is very fast.
2. Import the scientific computing packages with
1 2
$ brew update && brew upgrade $ brew tap homebrew/science
If you see any warnings, run
1
$ brew doctor
and follow any suggestions to fix the problem. And then re-import the packages as follows
1 2
$ brew untap homebrew/science $ brew tap homebrew/science
3. Install Octave
1
$ brew install octave --without-docs
The option –without-docs above is to suppress errors due to missing Tex installation.
4. Install gnuplot
As gnuplot will automatically be installed with octave, but without support for X11. So we need to reinstall it properly.