Artificial Intelligence (AI) or Human Intelligence (HI)?
It is not always obvious to determine using AI or HI. If you feel confident to have sufficient data to train sophisticate models, you may prefer using AI. Otherwise, using HI based rules is a more straight way tackling the problems. In practice, a hybrid solution combining both AI and HI is usually a wise choice.
Classification or Regression?
It all depends on the output of the problem. If the outcome is continuous, use regression, otherwise classification. In the digital world, nothing is really continuous. So, if there are too many categories, use regression is a wiser choice.
Do I need preprocessing?
It is rare case that no preprocessing is required. Data usually contains a lot of noise. If the raw data is feed into the learning algorithm, unpredictable outcome may be obtained. Filtering the extraneous data before doing the learning, and most important, also apply the filter before applying the algorithm in your real system. Once you encounter an extraneous event, use HI to determine the output to your end user.
Complex or Less complex?
In the world of learning algorithm, the complexity of the problem is important to choose to apply a “legacy” algorithms like random forest, SVM, or to apply a “cutting-edge” algorithm like CNN. Though DNN beats the smartest people in some areas, it is still quite big for some applications, e.g., activity classification on smartphones. Also, keep in mind that those super powerful algorithms need tons of data as learning input. So, before tasting the cutting-edge techniques, be sure to prepare enough “food” for them.
How to avoid over-fitting?
The cue comes from cross validation. Depending on how much data you have, you make take out 30% data for testing, and the left 70% for training. Or, you may split the whole data set as 10 splits. You take out 1 split for testing and the left 9 splits for training. If you have only few data, use leave one out cross validation.
What’s the cost?
Learning algorithms typically treat all output result neutrally, which however is rare in practice. So, be sure to consider about your cost function, and apply it to the learning algorithm. There are a few ways of applying a cost function given a learning algorithm as a blackbox.
How domain-knowledge comes in?
In general, domain knowledge belongs to HI. Here, I simply want to emphasis that domain knowledge may come in multiple ways. For example, the output of a classification algorithm may be smoothed with a HMM smoother powered by domain knowledge. Also, choosing the features requires deep understanding about the problem to solve. Make a stretch algorithm framework for the problem and then feed more and more domain knowledge in brain to make it better.
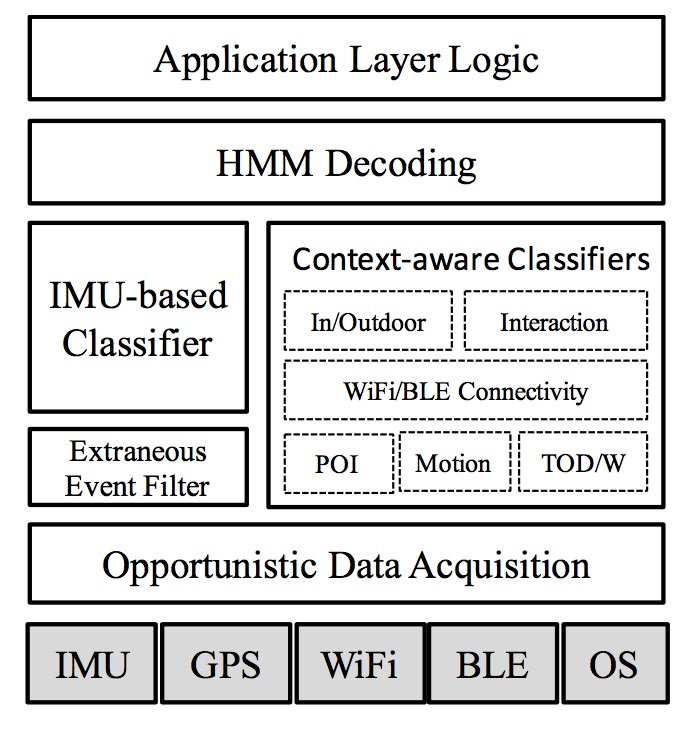
Finally, I want to put a picture of the architecture that I designed for transportation activity detection on smartphones.