
What’s consensus?
It allows a collection of machines to work as a coherent group that can survive the failures of some of its members.
It means not only a group of machines reach a final decision for a request, but also the state machine is replicated across these machines, so that some failures do not affect the functioning. Raft is a consensus algorithm seeking to be correct, implementable, and understandable.
The thesis is very well written. It is much more comprehensive compared to the NSDI paper. Implementing Raft based on the thesis shouldn’t be too difficult (of course, also not trivial). The author also built a website putting all kinds of helping things there. I read the paper and decide to take some notes here.

There are two key parts sitting in the core of the algorithm:
Leader election
The election is triggered by a timeout. If a server failed to detect heartbeats from the current leader, it start a new term of election. During the term, it broadcast requests to collect votes from other servers. If equal or more than majority of servers reply with a vote, the server becomes the leader of this term. The “term” here is a monotonically increasing logic time. From the perspective of a server receiving the vote request, it decides whether to give the vote based on a few considerations. First of all, if the sender even falls behind the receiver in terms of log index, the receiver should not vote for it. Also, if the receiver can still hear the heartbeats from current leader, it should not vote too. In this case, the requester might be a disruptive server. In other cases, the receiver should vote for the sender.

Log replication
Once a server becomes the leader, it’s mission is simply replicate it’s log to every other follower. The replication means make the log of a follower exactly the same as the leader. For each pair of leader and follower, the leader first identify the highest index where they reach an agreement. Starting from there, the leader overwrite its log to the follower. The leader handles all requests from clients. Once it receives a new request, it first put the request into its own log. Then, it replicate the request to all followers. If equal or more than majority followers (including the leader itself) answer the replication request with success, the leader apply the request into its state machine (this is called commit). The leader put the new log index into its heartbeats, so followers know if the request has been committed, after which each follower commit the request too.
More formal introduction of the core Raft could be found in Fig. 3.1 in the thesis paper. There are also a few extensions to make the algorithm practical to be used in production systems, such as the group management. I also found Fig. 10.1 a very good reference of architecture.
There are quite a lot of implementations of Raft, which could be found here. I also find a project named Copycat, with code here and document here. Copycat is a full featured implementation of Raft in java. Building your own application based on Copycat shouldn’t be too difficult. They provide an example of implementing a KV store based on Copycat in their source code here, which is used as the “Get Started“ tutorial. Another very important reason, why I think Copycat a good reference, is that it emphases the abstraction of state machine, client, server, and operations. Therefore, going through it’s document enhanced my understanding of Raft.
If you don’t want to build your own Raft, may be Copycat is worthwhile a try, though I haven’t any real experience beyond a toy project.
The annotated thesis could be found here.
A go-through case for understanding
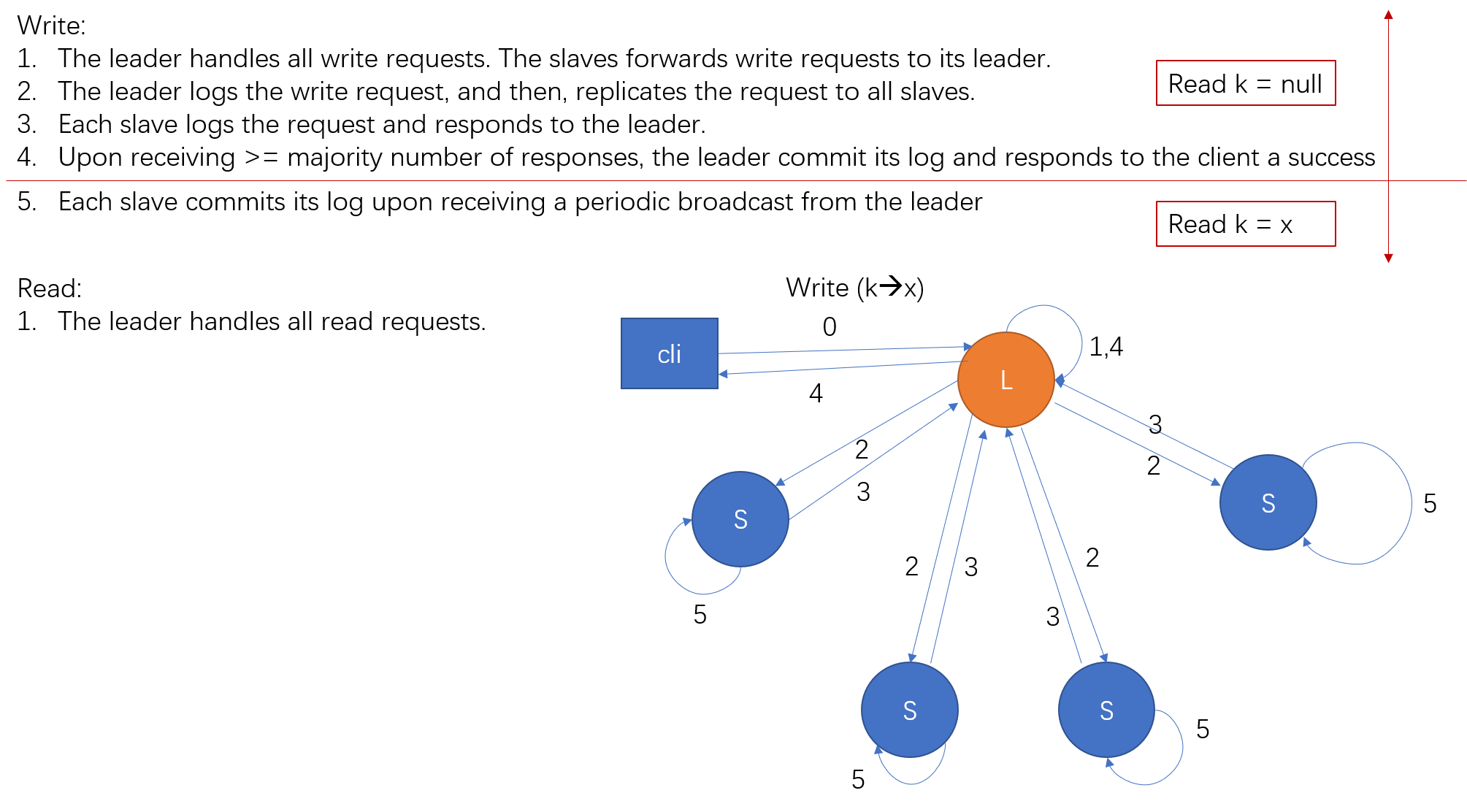
A typical request handling process is as follows:
- The client sends a request to the cluster;
- The leader handles the request by putting it to a WAL;
- The leader sends the request to all followers;
- Each follower puts the received request to its WAL, and responds to the leader;
- Once the leader has heard a majority number of responses from its followers, the leader commit the request by applying the WAL to its state machine;
- The leader inform the client that the request has been handled properly, and then, put the index of the request into its heartbeat to let all followers know the status of each request;
- Once the follower knows that the request has been committed by the leader, the follower commit the request too by applying it to its own state machine.
There are a few key points to understand in the process above:
1.Does the client always know if its request has been handled properly?
No. If the leader commits the request and then crashes, the client will not know if the request has been actually successfully handled. In some cases, the client will resend the request which may lead to duplicated data. It leaves for the client to avoid such kind of duplication.
2.How about the leader crashes before inform its followers that the request has been committed?
If the leader crashes, a follower will be elected to be the next leader. The follower must have the latest state according to the mechanism of Raft. Therefore, the next leader definitely has the WAL for the request, and the request has definitely been replicated across a majority number of hosts. Therefore, it is safe to replicate its state to all followers.
3.Key feature of a consensus algorithm (or strong consistency)?
Under normal situations, if there’s a state change, the key step changing the state should be always handled by a certain node. The state changing should be replicated to a majority number of followers before informing the requester a success. Each read request goes to that certain node as well. Once there’s node failures or networking partitions, the service stop working until returning to the normal situation again.