
读RabbitMQ文档的时候奇怪为什么它不支持负载均衡。后来看过别人写的Haproxy+RabbitMQ实现负载均衡,觉得似乎这样做就完美了,直到读到这篇文章《Load Balancing a RabbitMQ Cluster》。
这篇文章里介绍了RabbitMQ在队列备份时的一些细节:假设一个cluster里有两个实例,记作rabbitA和rabbitB。如果某个队列在rabbitA上创建,随后在rabbitB上镜像备份,那么rabbitA上的队列称为该队列的主队列(master queue),其它备份均为从队列。接下来,无论client访问rabbitA或rabbitB,最终消费的队列都是主队列。换句话说,即使在连接时主动连接rabbitB,RabbitMQ的cluster会自动把连接转向rabbitA。当且仅当rabbitA服务down掉以后,在剩余的从队列中再选举一个作为继任的主队列。
如果这种机制是真的,那么负载均衡就不能简单随机化连接就能做到了。需要满足下面的条件:
- 队列本身的建立需要随机化,即将队列分布于各个服务器;
- client访问需要知道每个队列的主队列保存在哪个服务器;
- 如果某个服务器down了,需要知道哪个从队列被选择成为继任的主队列。
于是,Load Balancing a RabbitMQ Cluster的作者给出了下图的结构。
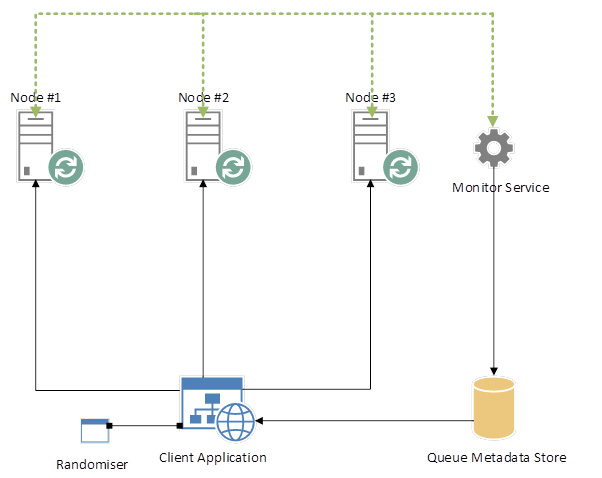
这还是颇有点复杂的。首先,在建立一个新队列的时候,Randomiser会随机选择一个服务器,这样能够保证队列均匀分散在各个服务器(这里暂且不考虑负载)。建立队列后需要在Meta data里记录这个队列对应的服务器;另外,Monitor Service是关键,它用于处理某个服务器down掉的情况。一旦发生down机,它需要为之前主队列在该服务器的队列重新建立起与服务器的映射关系。
这里会遇到一个问题,即怎么判断某个队列的主队列呢?一个方法是通过rabbitmqctl,如下面的例子:
./rabbitmqctl -p production list_queues pid slave_pids registration-email-queue <rabbit@mq01.2.1076.0> [<rabbit@mq00.1.285.0>] registration-sms-queue <rabbit@mq01.2.1067.0> [<rabbit@mq00.1.281.0>]
可以看到pid和slave_pids分别对应主队列所在的服务器和从服务器(可能有多个)。利用这个命令就可以了解每个队列所在的主服务器了。