在认知事物的过程中,一个人的外在表现通常是循环往复的。最常见的情况是,起初对某个领域知之甚少,感觉到自己的无知;随着不断学习,又会在某一阶段认为自己已经掌握了大部分知识;而更进一步的深入,又会觉得在许多地方理解不到位,无知感又随之而来。这种现象,可以用螺旋式台阶来比喻,正如下图的上面部分。
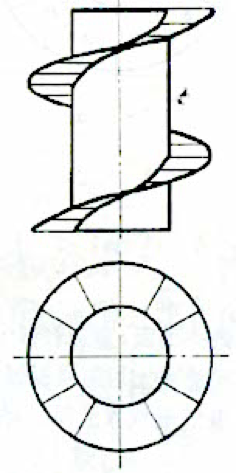
这会产生一个有趣的问题,虽然认识在逐步加深,也就好比沿着台阶不断上升,但将这些台阶投影到一个平面(如图下半部分)会发现不同高度的台阶会投影到同一个区域里,而这意味着什么呢?从内在看,这意味着某些观念或感觉的往复,正如开头的例子里无知感会反复出现;而从外在来看,则是人对外的表现形式有一定的类似。理解了这一点有两方面的好处:首先,在认知事物的过程中,不要因为出现往复感而焦虑,因为这是深入的必经之路,如果没有这种感觉反倒是有问题的;另外,更重要的是我们能够更加理性地观察和分析他人所处的状态。
如果不理解这种螺旋上升和投影的关系,当我们观察到某人的外在表现时,很容易把他们定位在错误的认知程度上。比如在学术上,大师往往能把非常复杂的问题用浅显的语言描述清楚,而一些只知道浅显原理的人也能说出类似的段子,如果不能理性观察,就容易把“浮于表面”错误看成“深入浅出”。再比如在当前的互联网公司里存在许多杂家,他们表面上什么都懂,却无一精通,其理解事物的深度有限,从而对整体的把握也是畸形的,这跟许多从业多年的人比起来,乍一眼看上去是类似的,需要多了解一点才能真正分辨出来。
看《国史大纲》里对战国时期的一系列的描述,包括废井田开阡陌、军人和商人替代贵族等等,总感觉能看到欧洲文艺复兴时期的味道,两者都是封建社会崩溃的过程。但是,为何欧洲随后横扫全球而当年“中国”只是实现了秦朝的大一统?两者类似螺旋上升的不同层次。从战国到文艺复兴,两者相隔千年,生产力在逐渐进步,因此放在战国时期,各国只能对内扩张对外兼并;放在欧洲,则各国有更强的实力去对外扩展和兼并欧洲以外更广大的世界。
2017-04-15更新
近年来中国的互联网行业大都沿袭野蛮生长的模式,其中以华为、阿里为成功的典型。虽然大家习惯认为BAT是一个梯队,但BT和A并非同一时代的企业,与那俩相比A要晚的多。野蛮生长的最大特点是少量精英+大量的廉价劳动力(即“铁打的营盘流水的兵”),最大的特点在工资低、无偿加班、强调狼性文化和价值观。原本奉行精英文化的公司(比如外企、百度),掉头学习这种野蛮模式以自救。
从时间轴上看,这只是生产力发展到一定阶段,为了迎合这种生产力而诞生的一种生产关系。随着各种技术的成熟,不再需要精英阶层从事一线生产活动,这些精英转而成为领导层去带领一些廉价劳动力完成过去看似无法完成的生产活动。然而,社会仍旧向前发展,将会进入下一阶段,而这个阶段又与上上个阶段表现出的现象类似。
简而言之,社会发展的方向是不断加深协作的深度,这将无法依赖现在的野蛮生长模式完成进化。在短期的将来,更合理的模式将是中等规模的精英间的协作。在人力资源受限的情况下,必然依赖全球的人才聚集,突破这种限制,一些高质量的开源项目正是在这种背景下完成的。适应这种状态的公司的模式不再大,依赖少量的精英人才分布式自由组合。为什么是少量呢?因为生产力的发展,已经不再需要那么多人了;为什么是分布式自由组合?因为这样的组织效率是最高的。
截止今天,仍然能看到市面上各种沿袭野蛮生长模式的公司,其中很多已经死掉了,或者在苟延残喘依赖风投的钱续命。另一些看似成功的公司,比如滴滴、膜拜、ofo等等等等,它们的命运让人拭目以待。那些近年来靠野蛮生长走向巅峰的公司,它们必将进入一轮刮骨疗毒般的清理门户。在将来的几年里,这些都值得期待~