
I recently read a serial of posts about the quorum mechanism in Amazon Aurora, which is a distributed relational database. These posts are:
post1: quorums and correlated failure.
post2: quorum reads and mutating state.
post3: reducing costs using quorum sets.
post4: quorum membership.
Reading the New Apache HBase MOB Compaction Policy
In case you want to understand more on MOB (Moderate Object Storage), you may refer to this issue. Basically, hbase was first introduced with capability of storing mainly small objects (<100k). Moderate objects stand for files from 100k to 10m.
Recently, there is a blog introducing the new compaction policy for MOB files. The problem with the initial approach is multiple compaction. For instance, the goal is to compact the objects created in one calendar day into one big file. The compaction process starts after the first hour. The objects created in the first hour are compacted into a temporal file. Then, the objects created in the second hour, and the temporal file created for the first hour are compacted into a new temporal file…
Understanding Chain Replication
I learned the idea of chain replication from hibari,
Hibari is a production-ready, distributed, ordered key-value, big data store. Hibari uses chain replication for strong consistency, high-availability, and durability. Hibari has excellent performance especially for read and large value operations.
Spark学习笔记
Spark与Scala在学习Spark之前务必对Scala有所理解,否则面对完全陌生的语法是很痛苦的。
Scala的一种入门方式是:
学习Scala 函数式程序设计原理。这是Scala作者自己开的课程。没什么比语言作者更加能理解这门语言的了,是切入Scala编程的最好入门方式。课程习题参考了《计算机程序的构造和解释》一书,非常经典。
阅读《Scala in depth》一书,对一些Scala的重点概念有更加详细的讨论。
根据特定的topic,Google各种网络资料。
Notes on Two-phase Commit
I recently came across a good description of two-phase commit from actordb’s document. I decide to borrow it as a note. The following is copied from actordb’s document:
3.2.3 Multi-actor transactions
Multi-actor transactions need to be ACID compliant. They are executed by a transaction manager. The manager is itself an actor. It has name and a transaction number that is incremented for every transaction.
Sequence of events from the transaction manager point of view:
- Start transaction by writing the number and state (uncommitted) to transaction table of transaction manager actor.
- Go through all actors in the transaction and execute their belonging SQL to check if it can execute, but do not commit it. If actor successfully executes SQL it will lock itself (queue all reads and writes).
- All actors returned success. Change state in transaction table for transaction to committed.
- Inform all actors that they should commit.
Sequence of events from an actors point of view:
- Actor receives SQL with a transaction ID, transaction number and which node transaction manager belongs to.
- Store the actual SQL statement with transaction info to a transaction table (not execute it).
- Once it is stored, the SQL will be executed but not committed. If there was no error, return success.
- Actor waits for confirm or abort from transaction manager. It will also periodically check back with the transaction manager in case the node where it was running from went down and confirmation message is lost.
- Once it has a confirmation or abort message it executes it and unlocks itself.
Problem scenarios:
- Node where transaction manager lives goes down before committing transaction: Actors will be checking back to see what state a transaction is in. If transaction manager actor resumes on another node and sees an uncommitted transaction, it will mark it as aborted. Actors will in turn abort the transaction as well.
- Node where transaction manager lives goes down after committing transaction to local state, but before informing actors that transaction was confirmed. Actors checking back will detect a confirmed transaction and commit it.
- Node where one or more actors live goes down after confirming that they can execute transaction. The actual SQL statements are stored in their databases. The next time actors start up, they will notice that transaction. Check back with the transaction manager and either commit or abort it.
摄影笔记
焦段选择的一些感想:
广角(<35mm)
- 场面干净:由于广角会摄入较广的场景,所以必须保证其中不要有不希望被包括的主体
- 中心突出:没有中心的广角构图是非常失败的,这比其它焦段更加要求中心突出
- 线条整齐对称:没有细密整齐的线条,广角会非常乏味,这些线条可以是建筑、地面的纹路、天际线等等
- 身临其境:广角照片给人的印象是身历其境,所以角度一般不能太平庸,要么居高临下,要么自底向上
- 多元素:元素可以多一点但最好是能够相互呼应的
中焦(35mm~70mm)
- 现实感:由于其呈现的效果更加接近人眼所以能给人一种“旁观”的感觉,更加适合拍摄纪实的题材,其带来的震撼感要高于其它焦段
- 距离变化:在这个焦段范围中,一点点变化都能对拍摄距离产生较大影响
长焦(>70mm)
- 微距:把较远处的主体拍到眼前是长焦的主要作用之一
- 压缩场景:由于长焦会把多个主体间的距离弱化,很像中国画的感觉,体现的是一种平面的美感
- 少元素:元素尽量少一点,画面简单一点,弱水三千只取一瓢
- 虚化加成:由于长焦带来的虚化加成,在稍微大一点的光圈下能达到所谓“空气切割”的感觉
场景 vs. 焦段
- 苏州园林:原本是为了人眼优化的布景,更加适合中焦和长焦
- 城市建筑:广角更能呈现出震撼的感觉,加上建筑的线条在广角中更具有表现力;一些广场上的建筑由于没有遮挡,在没人的时候也可以用长一点的焦段
- 人像:跟场景有关,在场景杂乱的地方就老实用中长焦大光圈虚化;在户外视场景而定广角可以突出人与宏达场景的相映,中焦更接近生活,长焦可以捕捉一些在无干扰情况下的活动,总而言之还是跟背景有关系
一些原则
- 色彩尽量少一点,不要给人一种杂乱的感觉
- 一定要有主体,不然没有着眼点
- 场景中的元素除非必要尽量不要包括进来
Setup SBT Development Environment
Setup JDK following Oracle guidance.
Setup SBT
No matter which platform you are on. I recommend downloading the zip archive directly.
Put the following into ~/.sbt/repositories:
1 | [repositories] |
Run sbt and sbt console. If you see all downloads from aliyun, you’ve setup it successfully. Test creating a new SBT project in intellij to see if everything ok.
Notes on Multi-versioned Storage
I recently read the Spanner paper. I realized that I cannot understand the idea of TrueTime and Non-blocking read well. Therefore, I did some research by googling the concept of non-blocking read, and came across this mysql document. After reading it, I realized that my understanding of multi-versioned storage is incorrect. So I decide to put some notes here.
The key points of multi-versioned storage are:
- version -> the creation wall clock time of the object (or a vector time)
- timestamp -> the query time of the object
- the association between the metadata and content should never be changed
Each object is associated with a set of metadata. The metadata contains a timestamp field indicating the version of this object. For a concrete example, let’s define a storage model as follows:

Each metadata contains three fields
| Field | Description |
|---|---|
| name | name of the object. objects with the same name are deem to be the same object |
| ctime | creation time |
| deleted | 1 means a tombstone |
| extra | some extra metadata for this object |
Let’s use typical operations to clarify the usage of this data model.
Put
Put is adding a new versioned object into the storage. In the figure above, the first “obj1” is inserted at 2017-04-01 11:30:12. Inserting another object with the same name is simply adding a new entry to the table pointing to the new content. When an object is requested from client, only the one with the latest timestamp is returned. Therefore, from 2017-04-01 11:30:12 to 2017-04-02 11:31:25, the first obj1 is visible. After 2017-04-02 11:31:25, the client see only the second obj1. With this data model, there is no need to block writes during reading this object, since each operation is based solely on its timestamp.
Delete
Delete is simply by putting a tombstone for a certain object. Like the third obj1 in the example. No content is presented for this entry. The objects with a tombstone as the latest entry will be filtered out if requested from clients.
Update
In this context, update is different from putting new contents into the object, but altering the object’s metadata (e.g., the extra field in the table). Updating the fields beyond the unique key is less a problem. If we need to update even the name of the object, we need to perform two steps: (1) delete the original object; (2) put a new object with the new metadata. One need to keep these two steps in an atomic transaction.
Search
Search is usually based on metadata to find a set of objects. The difference with multi-versioned storage is that we only return an object with the latest timestamp. This could be achieved with a select clause like
1 | SELECT t.* FROM (SELECT * FROM table WHERE xxx AND ctime < NOW() ORDER BY ctime DESC) t GROUP BY t.name |
We then filter out tombstones reside in the result set.
Get
Get is first searching for the latest object before the operation time. Then, the pointer of content is handed over to the client. The client should read the content as soon as possible. Otherwise, the content may be deleted due to recycling.
Compact
Compact refers to merge a set of contents into a big one. This is useful for example for HDFS to relief the name node’s burden of storing a large number of small files. The implementation of compaction is a bit tricky. One first merge the target set of contents into a big file. Then, insert a new entry for each related object within an atomic transaction. For clarification, let’s suppose we need to compact obj2 and obj3 in our example. We first create a new content with both contents from the original obj2 and obj3. Then, we add new entries for obj2 and obj3, respectively. The tricky part is that the ctime for these two entries are just 1 second larger than the original two.
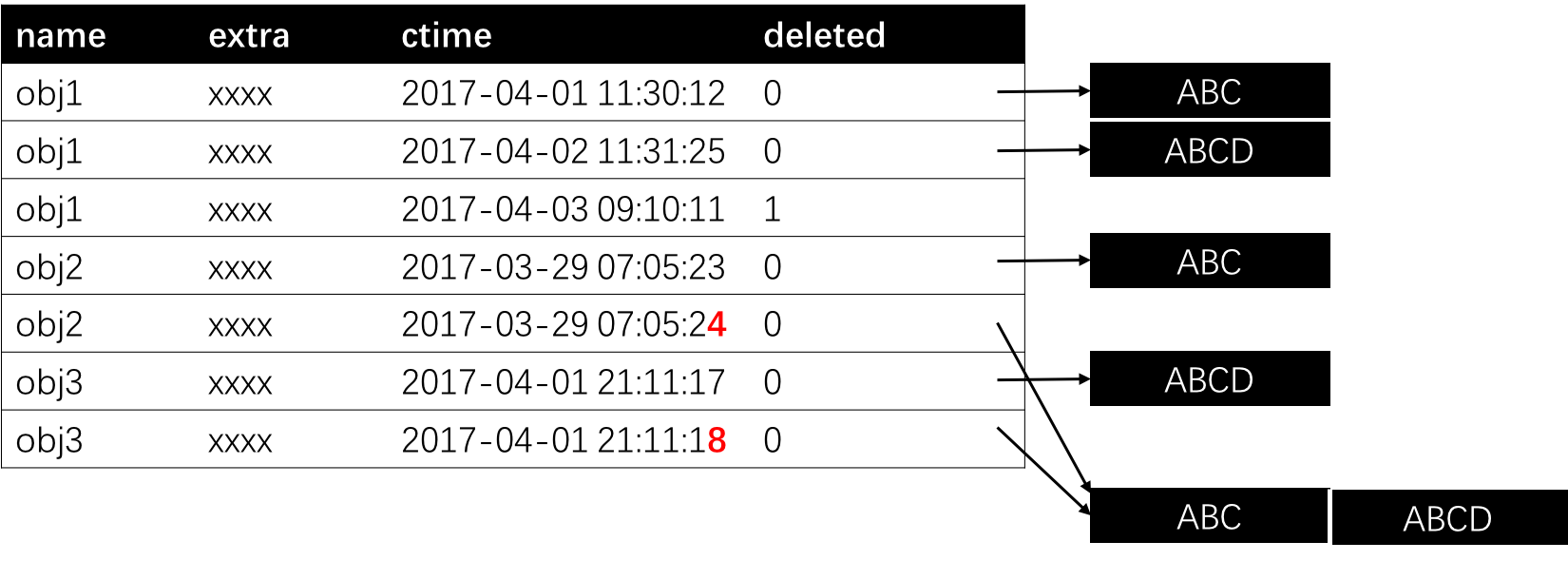
This may sounds weired at first. But think about the situation that a new entry for obj2 is put after we started but not finished compaction. In this case, the new content could be covered by the compaction if the ctime is larger than the new entry. We add 1 to the ctime. So, the new entry will either be later, or conflict with the compaction, leading to a failure. Upon such failure, the client simply retry to submit the new content. This should not be a real problem since compaction is a rare operation.
One may wonder why not simply updating the pointers in the original entries for obj2 and obj3. This actually breaks the third key points we mentioned at the beginning. It is important not changing the association. For example, if we want to get an object during compaction, reading may fail since the old contents may be deleted. Also, stale contents may be produced. More importantly, we may need very complicated transaction controls.
Recycle
Recycle is used to delete all deleted objects. The deleted objects could be find by searching for tombstones in the table. If a tombstone is detected, all entries before that can be deleted physically, including the tombstone itself. Delete a single content is straightforward. However, if a content is merged into a big file, we can carry out a similar process like compaction to delete the content physically. Old-versioned entries can also be recycled. Both recycling for deleted and old-versioned entries follows a certain policy. We can delete an entry once it has been out dated for a few days. This duration shouldn’t be too soon. Otherwise, we may recycle content being or to be read.
One can see that, with this multi-versioned storage model, all operations are much simpler without dependency to a locking system. We even do not rely on transaction, if compaction is not necessary. Let’s return to the three key parts at the beginning of this note. With a timestamp field, we already get the sense of version. As discussed above, the operation timestamp is critical as we need it to determine which object should be put into the result set. If data is stored across multiple machines, we need to synchronize their clock precisely. TrueTime is a API expose the uncertainty of time among different machines, and thus is critical for such large scale storage implementation. Finally, the association should not be broken, otherwise, we need complicated mechanisms to fix the issues it incurs.
Notes on Implementing A Lock System
Recently, I got the job of building a locking utility. I started by learning from existing locking services, i.e., zookeeper and mysql, since they already have been widely accepted. Zookeeper has this page introducing how to build locks. I also find this page details how lock implemented for mysql innodb table rows. After reading these materials, as well as some others. I found a locking utility could be simple, and also could be quite complicated. So I decided to make a note here to summarize my understandings.
A lock is essentially a flag claiming the right of a deterministic resource. In mysql, the locking of a range is mapped to a set of data pages, which is thus deterministic as well. The simplest form of lock is a single write lock of one resource, e.g., a file. One could implement this based on zookeeper by creating a node with a certain name. For example, if I want to lock the file “/home/liqul/file1”, I’d put a node with the same name of the file into zookeeper. If the creation returns with success, I got the lock for the file. In contrast, if I failed in creating the node, it means the lock of the file is already held by someone else. If I cannot obtain the lock, I may backoff for a while and retry afterwards. The one holding the lock should release it explicitly. Otherwise, the file can never be used by others any more.
I note that this is much simpler compared with the lock recipe in this page. The zookeeper lock recipe brings two useful features: blocking and session-aware. Blocking means that if I failed to obtain the lock now, I will wait until the lock being released by all peers queuing before me. Session-aware means that if I crash, my application for the lock also disappears. The latter is useful to avoid forgetting to release the lock as discussed in the previous paragraph. To implement these two features, one should setup a client-server architecture. Also, to achieve blocking lock, one need a queue for each resource. Sometimes, we however prefer non-blocking locks, which is not discussed in the zookeeper recipe.
Read-write lock is an extension of the write-only lock. Zookeeper also has a dedicated recipe for it here. Implementing a read-write lock is non-trivial. Let’s explain this problem with a concrete example. Suppose A wants to acquire a read lock of a file F, while B wants a write lock to F too. A naive implementation may be as follows:
1 | 1 *A* checks if there's any write locks to *F* |
The “check and then lock” pattern simply doesn’t work correctly. In zookeeper, they rely on sequential nodes and watcher to work around this problem, where each peer always first inserts a node and then check if itself obtains the lock. If not, the peer put a watcher onto the current holder of the lock. Another workaround is to first obtain a global write pre-lock before any operation. With a pre-lock the above procedure becomes:
1 | 1 *A* acquires the pre-lock |
One obvious drawback of the second workaround is that even two locks have no conflict, they still need to perform one after another. To avoid this problem, the lock utility need to maintain a conflict matrix for each pair of locks being processed or pending (should be marked separately). If a pending lock is not conflicting with any lock processed, it obtains the pre-lock right away. Otherwise, it is put into a queue waiting for all conflicting locks being clear. A short version is to only consider read and write locks separately.
Another extension is to achieve atomicity for a set of locks. For this purpose, one need to treat the whole set as “one” lock. And the handling of it is quite similar with what we have discussed above. For instance, if you want to implement with zookeeper, you may need to insert all the locks and then set watchers for a set of conflicting locks. Only after all conflicting locks being clear, you obtain the locks. Without zookeeper, one can also use the pre-lock solution as described above. A conflict matrix is necessary to avoid deadlock if you want to process the sets of locks in parallel.
In general, zookeeper is quite ready for customizing into your own locking service. However, it does has its own drawbacks. For example, it is not clear how to implement non-blocking read-write locks. If you have metadata for your locks, and you want to search in the metadata, zookeeper may be painful. At this time, using a mysql database may be a good choice, though you need to avoid some pitfalls discussed in this article.
Notes on Using "Select ... For Update" for Uniqueness in Mysql
I encountered a deadlock recently. Similar questions have been asked on StackOverflow, e.g., this and this. But the answers didn’t really explain why this happens.
The situation is quite easy to reproduce @ Mysql 5.7.17 (also tested on other versions in 5.5 or 5.6):
1 | CREATE TABLE `test` ( |
session11
2start transaction;
select * from test where val='pre-lock' for update;
session21
2start transaction;
select * from test where val='pre-lock' for update;
session11
insert into test set val='/a/b/c';
session21
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
The result of show engine innodb status:
1 | LATEST DETECTED DEADLOCK |
My objective is to use select ... for update as a uniqueness check for a following sequence of insertions. I expected that Tnx 2 would wait until Tnx 1 released the lock, and then continue its own business. However, Tnx 2 is rolled back due to deadlock. The innodb status looks quite confusing. Tnx 1 is holding and waiting for the same lock.
After some research, though I still cannot figure out the root cause, my perception is that the insertion in Tnx 1 acquires a gap lock which is somehow overlapping with the gap lock by the select ... for update. And therefore, this create a deadlock where Tnx 1 waits for Tnx 2 and Tnx 2 waits for Tnx 1.
During my research, I found that the right use case for select ... for update is as follows:
1 | start transaction; |
The rows being mutated should be explicitly locked by the select ... for update. Also, the condition should be as clear as possible. For example, put only an unique key in the condition. This is to make the gap lock with a simple and clear range, in order not to cause deadlocks.
Generally, using select ... for update is non-trivial since the underlying locking mechanism seems quite complicated. For my scenario, I got two workarounds:
- Disable gap locks by setting the isolation level to
READ COMMITTED. - Apply
select ... for updateon a row from another table, which avoid possible lock overlap.