
I recently read the Spanner paper. I realized that I cannot understand the idea of TrueTime and Non-blocking read well. Therefore, I did some research by googling the concept of non-blocking read, and came across this mysql document. After reading it, I realized that my understanding of multi-versioned storage is incorrect. So I decide to put some notes here.
The key points of multi-versioned storage are:
- version -> the creation wall clock time of the object (or a vector time)
- timestamp -> the query time of the object
- the association between the metadata and content should never be changed
Each object is associated with a set of metadata. The metadata contains a timestamp field indicating the version of this object. For a concrete example, let’s define a storage model as follows:

Each metadata contains three fields
| Field | Description |
|---|---|
| name | name of the object. objects with the same name are deem to be the same object |
| ctime | creation time |
| deleted | 1 means a tombstone |
| extra | some extra metadata for this object |
Let’s use typical operations to clarify the usage of this data model.
Put
Put is adding a new versioned object into the storage. In the figure above, the first “obj1” is inserted at 2017-04-01 11:30:12. Inserting another object with the same name is simply adding a new entry to the table pointing to the new content. When an object is requested from client, only the one with the latest timestamp is returned. Therefore, from 2017-04-01 11:30:12 to 2017-04-02 11:31:25, the first obj1 is visible. After 2017-04-02 11:31:25, the client see only the second obj1. With this data model, there is no need to block writes during reading this object, since each operation is based solely on its timestamp.
Delete
Delete is simply by putting a tombstone for a certain object. Like the third obj1 in the example. No content is presented for this entry. The objects with a tombstone as the latest entry will be filtered out if requested from clients.
Update
In this context, update is different from putting new contents into the object, but altering the object’s metadata (e.g., the extra field in the table). Updating the fields beyond the unique key is less a problem. If we need to update even the name of the object, we need to perform two steps: (1) delete the original object; (2) put a new object with the new metadata. One need to keep these two steps in an atomic transaction.
Search
Search is usually based on metadata to find a set of objects. The difference with multi-versioned storage is that we only return an object with the latest timestamp. This could be achieved with a select clause like
1 | SELECT t.* FROM (SELECT * FROM table WHERE xxx AND ctime < NOW() ORDER BY ctime DESC) t GROUP BY t.name |
We then filter out tombstones reside in the result set.
Get
Get is first searching for the latest object before the operation time. Then, the pointer of content is handed over to the client. The client should read the content as soon as possible. Otherwise, the content may be deleted due to recycling.
Compact
Compact refers to merge a set of contents into a big one. This is useful for example for HDFS to relief the name node’s burden of storing a large number of small files. The implementation of compaction is a bit tricky. One first merge the target set of contents into a big file. Then, insert a new entry for each related object within an atomic transaction. For clarification, let’s suppose we need to compact obj2 and obj3 in our example. We first create a new content with both contents from the original obj2 and obj3. Then, we add new entries for obj2 and obj3, respectively. The tricky part is that the ctime for these two entries are just 1 second larger than the original two.
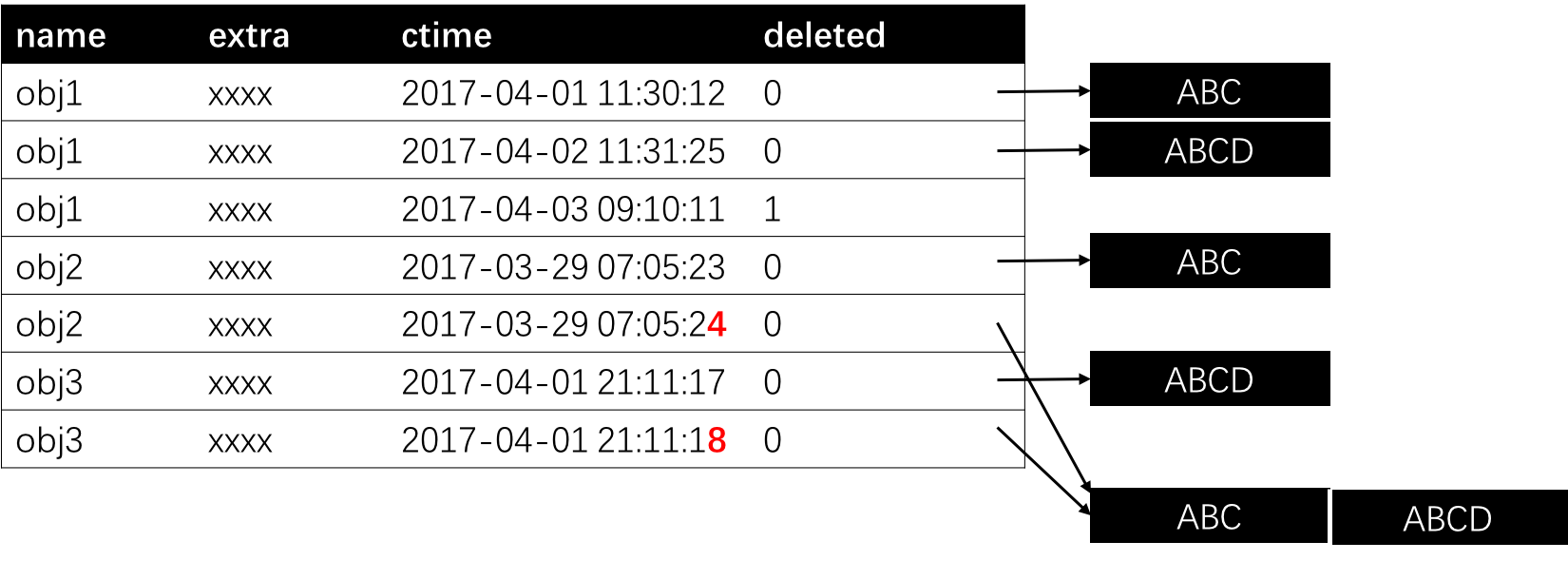
This may sounds weired at first. But think about the situation that a new entry for obj2 is put after we started but not finished compaction. In this case, the new content could be covered by the compaction if the ctime is larger than the new entry. We add 1 to the ctime. So, the new entry will either be later, or conflict with the compaction, leading to a failure. Upon such failure, the client simply retry to submit the new content. This should not be a real problem since compaction is a rare operation.
One may wonder why not simply updating the pointers in the original entries for obj2 and obj3. This actually breaks the third key points we mentioned at the beginning. It is important not changing the association. For example, if we want to get an object during compaction, reading may fail since the old contents may be deleted. Also, stale contents may be produced. More importantly, we may need very complicated transaction controls.
Recycle
Recycle is used to delete all deleted objects. The deleted objects could be find by searching for tombstones in the table. If a tombstone is detected, all entries before that can be deleted physically, including the tombstone itself. Delete a single content is straightforward. However, if a content is merged into a big file, we can carry out a similar process like compaction to delete the content physically. Old-versioned entries can also be recycled. Both recycling for deleted and old-versioned entries follows a certain policy. We can delete an entry once it has been out dated for a few days. This duration shouldn’t be too soon. Otherwise, we may recycle content being or to be read.
One can see that, with this multi-versioned storage model, all operations are much simpler without dependency to a locking system. We even do not rely on transaction, if compaction is not necessary. Let’s return to the three key parts at the beginning of this note. With a timestamp field, we already get the sense of version. As discussed above, the operation timestamp is critical as we need it to determine which object should be put into the result set. If data is stored across multiple machines, we need to synchronize their clock precisely. TrueTime is a API expose the uncertainty of time among different machines, and thus is critical for such large scale storage implementation. Finally, the association should not be broken, otherwise, we need complicated mechanisms to fix the issues it incurs.