
实验代码和输出
实验代码是基于作者原来的代码稍微修改而来,main函数如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19var (
nodes = make(map[int]*node)
)
func main() {
// start a small cluster
nodes[1] = newNode(1, []raft.Peer{{ID: 1}, {ID: 2}, {ID: 3}})
go nodes[1].run()
nodes[2] = newNode(2, []raft.Peer{{ID: 1}, {ID: 2}, {ID: 3}})
go nodes[2].run()
nodes[3] = newNode(3, []raft.Peer{{ID: 1}, {ID: 2}, {ID: 3}})
go nodes[3].run()
// Wait for leader election
for {
time.Sleep(100 * time.Millisecond)
}
}
在上面的这段代码里首先创建了3个节点,然后程序进入休眠等待节点竞争leader。程序的输出如下
1 | # 阶段1:节点初始化数据结构 |
节点的基本数据结构
正常情况下,初始化节点的代码在/raft/node.go里的StartNode方法。每个Node结构都关联到一个raft结构(定义在/raft/raft.go里)。其中Node负责与应用线程交互,而raft负责实现Raft协议的状态机,根据Node的输入raft产生相应的输出。
SoftState和HardState
在实现里有两种状态,稍微说明一下。在Raft作者的论文里,图3.1里列举了不同节点需要保存的状态,分为Persistent state和Volatile state。其中Persistent state包括currentTerm、votedFor和log[],这三个数据的前两个定义在HardState结构里(/raft/raftpb/raft.pb.go),而log[]则在Storage里维护,例如MemoryStorage里的ents数组。与论文不同的地方,在HardState里还包含了Commit,即论文图3.1里Volatile state里的commitIndex(todo:理解这里区别的含义)。SoftState与图中的Volatile state没有直接关系,其中包含了节点当前leader的id,以及节点当前的状态(leader还是follower等)。
此外,观察etcd/raft的实现发现,在MemoryStorage的初始化过程中,会向ents里写入一个dummy entry;而在ApplySnapshot方法里会在压缩完历史的entry之后初始化ents时写入一个特殊的entry,仅包含snapshot中最后一个entry的term和index。因此,在任何时刻在ents数组中的第一个元素都不是真正的entry,在一些处理过程中需要注意这一点(例如MemoryStorage的FirstIndex接口实现)。
Log的状态
完整的管理entry(或称为log)的结构是raftLog(参考/raft/log.go)。其中主要的属性,
| 属性 | 说明 |
|---|---|
| unstable | 记录所有收到但未成功复制到多数节点的日志,或尚未持久化的snapshot |
| committed | 记录最大的已经被复制到多数节点的日志 |
| applied | 记录最大的已经被应用到状态机的日志 |
| storage | 记录已经持久化的日志,和最新的已经持久化的snapshot |
每个entry都应该按照顺序先是unstable,然后是committed,最后才是applied,这个顺序不能乱。unstable和storage分别记录了未持久化和已持久化的entry和snapshot。
Peer列表
Raft论文图3.1里,作为leader,还需要维护两个状态,即nextIndex[]和matchIndex[]。这两者的实现在/raft/progress.go里,其中的主要结构体Progress用于记录每个follower节点的进度。其中match和next的定义分别是:
- match:follower与leader间一致的最大的entry
- next:leader下一个要复制到follower的entry
代码库里专门有一个markdown文件来说明这些概念及其使用方式,在/raft/design.md。正常情况下,follower与leader的entry列表应该完全一样,但由于leader处理新接收到的entry;节点故障而导致新一轮选举;有新节点加入,follower与leader之间出现不一致。这时候leader首先要了解follower的进度与自己进度的区别,此时的follower处于probe状态。如果follower接收并成功复制来自leader的entry,那么follower进入replicate状态,leader一次可以发出大于一条entry以提高传输效率。
在未了解follower的进度时,leader的行为是设置match=0和next=lastIndex+1。这样做是假定follower已经复制了所有leader上的日志。下一次leader向其follower发起复制的时候,如果follower实际上落后一些,会reject新的日志,并会告知leader自己的当前状态,leader根据情况再协调后续的发送。这里的逻辑参考/raft/raft.go里的handleAppendEntries实现。
snapshot相关的过程留在后续分析。
增加peer节点
通常情况下在集群初始化时都会有多个节点,例如在
1 | nodes[1] = newNode(1, []raft.Peer{{ID: 1}, {ID: 2}, {ID: 3}}) |
里在初始化节点1时就向它的构造方法里传入了三个节点ID。考察StartNode方法(/raft/node.go)可以清楚的看到,对每一个ID,当前都会往日志里主动增加一条ConfChangeAddNode消息。这其实是在模仿节点从网络接收到了增加节点的配置消息,这两者后续的处理逻辑是相同的。
Raft节点的线程逻辑在node.run方法里。Run的逻辑大致是:
- 等待新的触发事件,例如接收到来自用户线程的写入请求;接收到来自网络的消息等等。
- 被触发后经过raft.Step来驱动Raft协议状态机,输出一些变化(由containsUpdates来检验)。这些变化可能包括节点状态变化,或者有新的消息要发送,或者有新的log要持久化等等。
- 如果有新的变化,那么组织一个Ready结构发送给用户线程,具体的网络和持久化操作都在用户线程完成。
回到增加peer节点的情况,以advancec和readyc(run方法开头定义的临时变量)为线索来整理执行的流程。下图梳理了用户线程(app.run)和Raft线程(node.run)的交互逻辑:
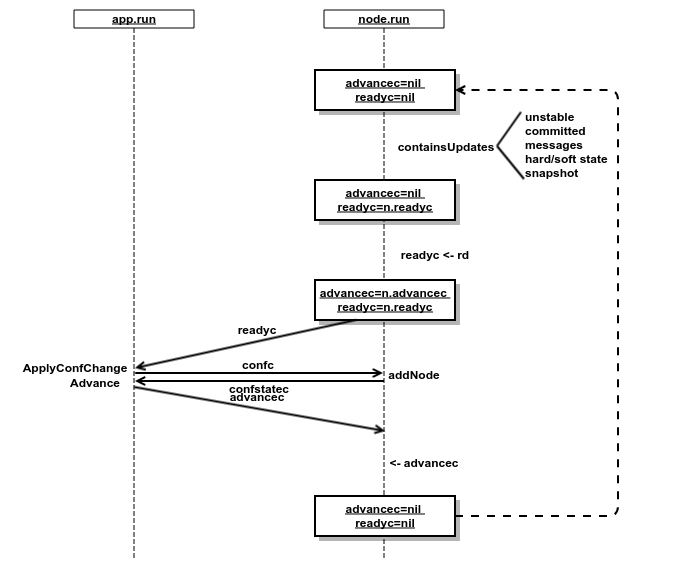
由于在初始化时已经指定了3个节点,所以在检查containsUpdates时会发现更新。后续的过程就如图1所示,在交互过程中用到的一系列channel也标记在图中的箭头上。在初始化的过程中,节点均处于follower角色,所以增加节点仅仅是向peer列表里增加了一些记录。
成为Leader的过程
在完成初始化之后,选举的过程是由超时来触发的。注意在初始化过程中,会执行becomeFollower(raft.go)将节点角色设置为follower。其中
1 | r.step = stepFollower // 设置step逻辑 |
包含设置step和tick逻辑的代码。在follower角色下,节点的超时行为是触发下一次选举;对应的,如果处于leader角色中,超时则是触发发送心跳消息。如果follower节点超时了,会给自己“发送”一个MsgHup消息,进而开始竞选leader。在竞选前的一些逻辑包括:
1 | // campaign |
随后,竞选节点需要邀请其它节点提名自己。当然,如果集群是只包含一个节点这种特殊情况,则不需要经过其它节点提名的过程而直接当选。发送邀请的过程如下:
1 | for id := range r.prs { |
论文3.6章讨论的是在选举过程中的安全问题,即如何避免一个log落后的节点竞选成为leader。作者提出了一个需要保证的性质——Leader Completeness Property,说明如下:
If a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered terms.
也就是一旦一条log确认被committed了,那么它一定要出现在下一个竞选成功的leader的日志里。这句话有两个问题:
如何判断一条log已经committed?
按照定义,committed的标准是在多数节点上复制成功。具体考虑一次写入操作,首先log通过网络复制到多数节点的日志;然后leader获得复制情况,确定完成复制后在本地commit日志;最后通过心跳消息通知其它节点commitment信息,接收到消息的其它节点在本地commit日志。从这个过程来看,leader和follower角色下的节点对同一条log是否已经被commit的认识时机是不同的,leader先于follower知晓该信息。如果leader已经知晓commitment但没来得及通知其它节点就掉线了,那么这条本来已经被commit的消息会怎么样呢?按照论文的讨论,由于其它节点并不知晓这条log已经被commit,所以如果一个没有包含这条log的节点当选为leader,那么这条本已经复制到多数节点的消息将被抹掉。所以,个人认为更为精确的说法是
一条log被commit,意味着它已经被复制到多数节点,并且多数节点已经知晓来自leader的commit的信息。
如何保证committed的log出现在后续竞选成功的leader?
按照上一个问题的逻辑,在MsgVote RPC里每个节点都应该包含自己已知的committed的日志的term和index,这样大家比较以后就能自然得出谁更加“up-to-date”一些。但是对比代码的实现细节,与论文的描述有所区别。在上面的代码片段里,raftLog.lastIndex和raftLog.lastTerm对应了index和term的值。而观察它们的实现,这里的“最后一条log”实际上包含了unstable结构里的数据,也就是包含没有被commit的日志。这样修改有什么影响呢?个人觉得这不会打破Leader Completeness Property,但会影响协议的行为。考虑一条日志被复制到多数节点但没有完成commitment,这时如果leader掉线,下一个被选举的leader一定包含这条尚未被commit的日志,因为那些尚未复制这条日志的节点无法得到足够多节点的支持。
节点接收到MsgVote后判断candidate的日志是否足够新的逻辑在raftLog.isUpToDate。
如何防止节点扰乱选举
解决了这两个问题,还有可能出现一种异常情况:如果一个失联节点不断增大自己的term,然后邀请其它正常工作状态下的节点参与选举,会扰乱集群的执行秩序。这个问题在论文的4.2.3章节讨论。
基本思想是如果一个节点能够接收到来自其leader的心跳,那么它不会参与选举。这个逻辑的实现可以查看raft.go下的inLease变量定义。