
Raft协议概览
Raft是什么?
Raft是一种共识协议。与Raft完成相同任务的系统有Chubby和Zookeeper,以及一些系统内置的完成类似功能的组件,例如Elasticsearch里的Zen-Discovery。简而言之,共识协议的目的是让一组节点在响应外界输入时能表现的像一个节点一样。共识系统往往应用于有主备结构的存储系统中,如果缺少这种协议,就无法避免数据错误。
共识协议非常重要,而且实现起来往往很容易犯错,因此大部分系统都依赖已经久经考验的系统,比如Zookeeper。选择自己实现共识组件需要莫大的勇气,看看这里就知道Elasticsearch曾经出现过许多一致性问题bug,而且还有一些没有被fix。Raft的提出是针对Paxos的,目的是为了提出一种容易被理解的共识协议。容易被理解也就意味着便于维护,不会有许多看起来”黑魔法“一样的技巧。
之前在这篇文章里已经有一些关于Raft的讨论。这次重新看Raft是希望基于etcd/raft的实现来详细梳理一遍其中的细节。Raft对一些需要实现强一致性的操作是如此重要,值得反复学习。
这个系列里一些重要参考的来源:
- Raft thesis:Raft作者的论文
- etcd/contrib/raftexample和etcd/raft:etcd里Raft的实现代码
- Raft:a first implementation:一篇有关如何简单使用etcd/raft库的blog
节点的三种状态
在一个正常运行状态(即集群能正常处理外部操作请求的情况)下的Raft集群中,节点分为leader和follower两种角色。其lLeader有且仅有一个,负责处理外部的操作请求;follower有多个,它们从属于leader,负责处理来自leader的指令。
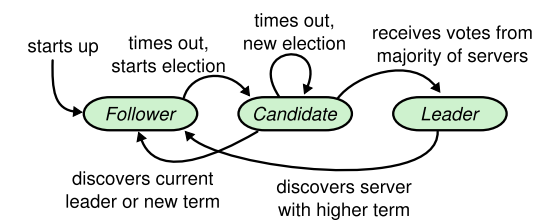
图1. Raft节点的状态转移图(原图Figure 3.3)
一个Raft节点有三种状态:follower、candidate和leader。图1中描述了三种状态之间的转移条件。正常运行状态下的节点要么处于follower状态,要么处于leader状态,而candidate属于follower和leader之间的中间状态,也是节点在非正常运行状态下所处的状态。
节点的初始状态是follower。当一个节点启动后,其状态即为follower。此后受到不同事件触发的影响会变更自己状态。Raft集群中的节点都会采用定期”广播“自己的状态。节点处于follower状态下,如果定期能接收到来自leader广播的消息,那么它会一直处于follower状态,而不会转移到candidate状态。
多个节点竞选leader的过程称为leader election,这是Raft协议中最重要的过程之一,将在后续分析代码时再详细梳理。需要稍微注意图1并不是完全的状态转移图,例如图1中并未包含节点在follower状态下接收到广播消息或选举消息的状态变化情况。此外,还有一个细节问题,若某个异常节点主动发起选举,那么其它节点监听到的选举消息里的term比自己当前的更大,那么其它节点是否应该参与选举呢?答案在Raft thesis的4.2.3章。所以图1只是一个基本的状态转移概览。
Log
Term是Raft中用来计量时间的概念,可以理解为阶段。当一个节点被选举为leader后,Raft系统进入稳定运行状态,随后如果leader节点停机则会进入下一轮选举。这里从上一次选举成功到下一次选举之间的时间即一个term。节点初始化的时候term=0,随后term越大也就意味着状态越新,term是单调增加的。处在正常运行状态下的所有Raft节点都有相同的term,所以如果一个节点监听到的来自其它节点的消息里包含的term比自己的更大,那么说明它自己处于异常状态;反之如果监听到消息里的term比自己的更小,那么这样的消息可以直接忽略掉。
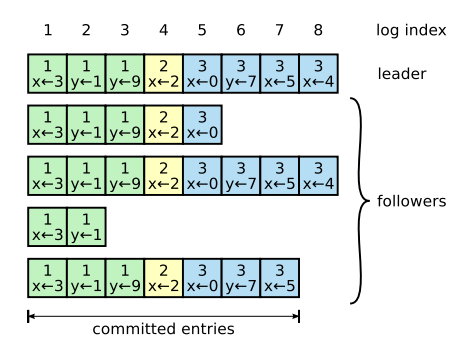
图2. Raft协议中的日志备份(原图Figure 3.5)
每条log对应一次请求,也唯一对应一个term。除了term以为,每条log在每个节点上还有一个唯一的index。如图2中所示,index是单调连续增加的自然数,这意味着任意节点上都不会出现index空缺。在稳定情况下,follower的log可以比leader落后,但不会出现不一致。例如,如果leader的index=4对应的log内容是x<-2且term=2,那么在所有follower上index=4的log都应该与leader相同。如果发生leader切换,在短期内有可能出现不一致的情况,但随后leader会要求所有follower完全复制自己的log(不一致的部分将被删除),那么等到稳定状态下,大家的log又会回到一致的状态。
请求处理工作流
Raft最核心的工作是使一组节点对来自外界的请求作出一致的反应。在一个正常运行的Raft集群里,只有leader能回应外部请求。这一点需要牢记,如果当前的leader因为停机而失效,那么必须等选举出下一个leader之后集群才能对外服务。在选举的过程中,集群是无法服务的,这会影响服务的HA,但又是得到强一致性操作必须的代价。图2是Raft集群的工作过程示意图。
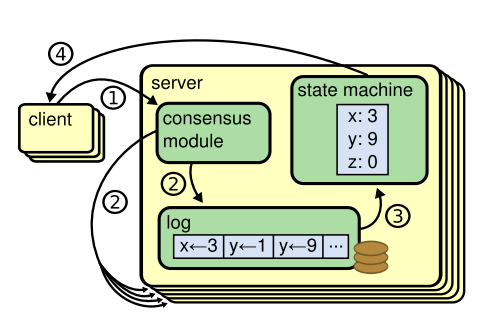
图3. Raft集群的工作过程(原图Figure 2.1)
在图3中,client发出外部写入请求(1),Raft集群的leader接收该请求后将请求内容写入本地log,同时将请求内容转发给所有follower(2)。每个follower在接收到请求后将内容写入自己本地log,并通知leader自己已经完成操作(这个步骤图2中没有标出)。leader一旦接收到大多数follower已经完成备份则把请求内容commit到本地的状态机(state machine),完成该操作后回复client写入完成(4)。随后在leader的广播里会包含最新的被commit的log序号,各follower监听到以后将写入操作commit到本地状态机。
图4精确描述了Raft基本协议中各角色的事件处理状态机。一些国外课程以Raft来作为课程作业,比如这里,提到:
In fact, Figure 2 is extremely precise, and every single statement it makes should be treated, in specification terms, as MUST, not as SHOULD.
文中的Figure 2就是图4。这张图算是对Raft基本协议作了一个非常精确又详尽的总结。

图4. Raft基本协议(原图Figure 3.1)