
Here is a very good explanation about eventual consistency and strong consistency. I’d like to borrow the two figures on that page below:
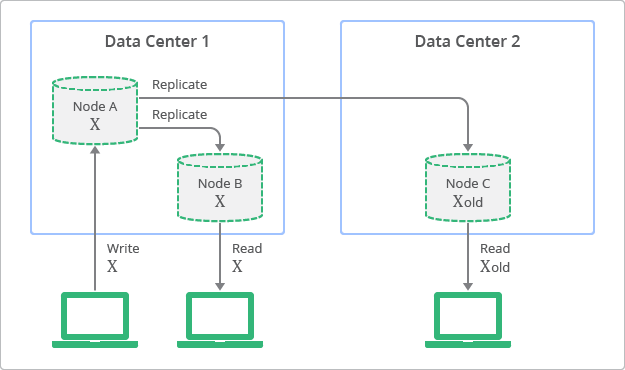
Fig. 1 figure for eventual consistency
In this example above, Node A is the master, which replicate X to its followers Node B and C. Suppose the time when X is successfully writen to Node A is t_1, and the time when X is replicated to Node B is t_2. Any time between t_1 and t_2, if a client reads from Node A, it gets the latest value of X. But if the client reads from Node B, it gets an old version of X. In other words, the result of a read depends on which Node the client reads from, and therefore, the storage service presents an inconsistent global view for the client.
In contrast, if the storage service provides a strong consistency semantic, the client should always read the same result. This figure below illustrates an example of strong consistency.
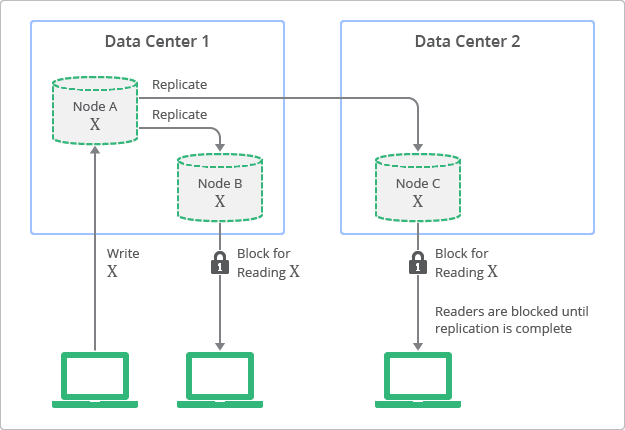
Fig. 2 figure for strong consistency
The single difference between Fig. 1 and Fig. 2 is that before X has been successfully replicated to Node B and C, a read request of X to Node B and C should be blocked. How about reading from Node A before all replications done? It should be blocked as well, and therefore, there is a missing ‘lock’ symbol in Fig. 2. The full picture should has the following steps:
- A client issues a write request of X to Node A;
- Node A locks X globally to prevent any read or write to X;
- Node A store X locally, and then replicate X to Node B and C;
- Node B and C store X locally and send Node A a response;
- After receiving from Node B and C, Node A release the lock of X and respond to the client;
These steps are only used to understand the basic idea of strong consistency, which is not necessary a best practice. If you want to know more details, research some real systems such as Spanner or Kudu.
While sounds more understandable for developers, strong consistency trades Availability for Consistency. In the instance shown in Fig. 2, a client may need to wait for a while before it reads the value of X. If the networking fails apart (for example, Node C is partitioned from Node A and B), any write requests to Node A will fail if each value is forced to have 3 replications. In addition, if the global lock service fails, the storage service will also be unavailable. In general, a storage service with strong consistency has much higher requirements to the infrastructure in order to function well, and therefore, is more difficult to scale compared to one with eventual consistency.